虫虫首页
|
资源下载
|
资源专辑
|
精品软件
登录
|
注册
首 页
资源下载
资源专辑
技术阅读
电 路 图
教程书籍
在线计算器
代码搜索
资料搜索
代码搜索
热门搜索:
fpga
51单片机
protel99se
机器人
linux
单片机
dsp
arm
Proteus
matlab
您现在的位置是:
虫虫下载站
>
资源下载
>
源码
> 数据挖掘-聚类-K-means算法Java实现
数据挖掘-聚类-K-means算法Java实现
资源大小:
17 K
上传时间:
2018-11-27
上传用户:
1159474180
资源积分:
2 下载积分
标 签:
K-means
Java
数据挖掘
聚类
算法
资 源 简 介
K-Means算法是最古老也是应用最广泛的聚类算法,它使用质心定义原型,质心是一组点的均值,通常该算法用于n维连续空间中的对象。
K-Means算法流程
step1:选择K个点作为初始质心
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
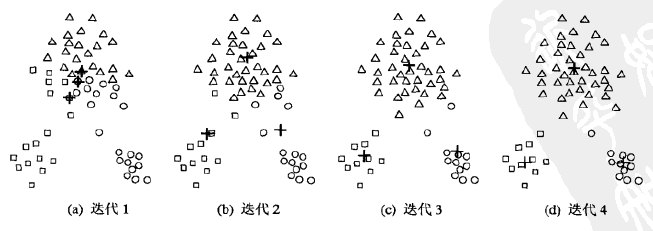
例如下图的样本集,初始选择是三个质心比较集中,但是迭代3次之后,质心趋于稳定,并将样本集分为3部分
我们对每一个步骤都进行分析
step1:选择K个点作为初始质心
这一步首先要知道K的值,也就是说K是手动设置的,而不是像EM算法那样自动聚类成n个簇
其次,如何选择初始质心
最简单的方式无异于,随机选取质心了,然后多次运行,取效果最好的那个结果。这个方法,简单但不见得有效,有很大的可能是得到局部最优。
另一种复杂的方式是,随机选取一个质心,然后计算离这个质心最远的样本点,对于每个后继质心都选取已经选取过的质心的最远点。使用这种方式,可以确保质心是随机的,并且是散开的。
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
如何定义最近的概念,对于欧式空间中的点,可以使用欧式空间,对于文档可以用余弦相似性等等。对于给定的数据,可能适应与多种合适的邻近性度量。
免注册下载
普通下载
相 关 资 源
您 可 能 感 兴 趣 的
收藏
赞(134)
踩(0)
用户登录/注册
×
确认下载
×
免注册下载
×
扫码关注并回复消息
发送: “MPS新能源” 获取验证码,验证成功后下载文件。
提交
请输入正确的验证码
用户登录
×
用户注册
×