
昨天在群里有朋友问:把进程绑定到某个 CPU 上运行是怎么实现的。
首先,我们先来了解下将进程与 CPU 进行绑定的好处。
进程绑定 CPU 的好处:在多核 CPU 结构中,每个核心有各自的L1、L2缓存,而L3缓存是共用的。如果一个进程在核心间来回切换,各个核心的缓存命中率就会受到影响。相反如果进程不管如何调度,都始终可以在一个核心上执行,那么其数据的L1、L2 缓存的命中率可以显著提高。
所以,将进程与 CPU 进行绑定可以提高 CPU 缓存的命中率,从而提高性能。而进程与 CPU 绑定被称为:CPU 亲和性。
设置进程的 CPU 亲和性
前面介绍了进程与 CPU 绑定的好处后,现在来介绍一下在 Linux 系统下怎么将进程与 CPU 进行绑定的(也就是设置进程的 CPU 亲和性)。
Linux 系统提供了一个名为 sched_setaffinity 的系统调用,此系统调用可以设置进程的 CPU 亲和性。我们来看看 sched_setaffinity 系统调用的原型:
int sched_setaffinity(pid_t pid, size_t cpusetsize, const cpu_set_t *mask);
下面介绍一下 sched_setaffinity 系统调用各个参数的作用:
pid:进程ID,也就是要进行绑定 CPU 的进程ID。cpusetsize:mask 参数所指向的 CPU 集合的大小。mask:与进程进行绑定的 CPU 集合(由于一个进程可以绑定到多个 CPU 上运行)。
参数 mask 的类型为 cpu_set_t,而 cpu_set_t 是一个位图,位图的每个位表示一个 CPU,如下图所示:

例如,将 cpu_set_t 的第0位设置为1,表示将进程绑定到 CPU0 上运行,当然我们可以将进程绑定到多个 CPU 上运行。
我们通过一个例子来介绍怎么通过 sched_setaffinity 系统调用来设置进程的 CPU 亲和性:
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
int main(int argc, char **argv)
{
cpu_set_t cpuset;
CPU_ZERO(&cpuset); // 初始化CPU集合,将 cpuset 置为空
CPU_SET(2, &cpuset); // 将本进程绑定到 CPU2 上
// 设置进程的 CPU 亲和性
if (sched_setaffinity(0, sizeof(cpuset), &cpuset) == -1) {
printf("Set CPU affinity failed, error: %s\n", strerror(errno));
return -1;
}
return 0;
}
CPU 亲和性实现
知道怎么设置进程的 CPU 亲和性后,现在我们来分析一下 Linux 内核是怎样实现 CPU 亲和性功能的。
本文使用的 Linux 内核版本为 2.6.23
Linux 内核为每个 CPU 定义了一个类型为 struct rq 的 可运行的进程队列,也就是说,每个 CPU 都拥有一个独立的可运行进程队列。
一般来说,CPU 只会从属于自己的可运行进程队列中选择一个进程来运行。也就是说,CPU0 只会从属于 CPU0 的可运行队列中选择一个进程来运行,而绝不会从 CPU1 的可运行队列中获取。
所以,从上面的信息中可以分析出,要将进程绑定到某个 CPU 上运行,只需要将进程放置到其所属的 可运行进程队列 中即可。
下面我们来分析一下 sched_setaffinity 系统调用的实现,sched_setaffinity 系统调用的调用链如下:
sys_sched_setaffinity()
└→ sched_setaffinity()
└→ set_cpus_allowed()
└→ migrate_task()
从上面的调用链可以看出,sched_setaffinity 系统调用最终会调用 migrate_task 函数来完成进程与 CPU 进行绑定的工作,我们来分析一下 migrate_task 函数的实现:
static int
migrate_task(struct task_struct *p, int dest_cpu, struct migration_req *req)
{
struct rq *rq = task_rq(p);
// 情况1:
// 如果进程还没有在任何运行队列中
// 那么只需要将进程的 cpu 字段设置为 dest_cpu 即可
if (!p->se.on_rq && !task_running(rq, p)) {
set_task_cpu(p, dest_cpu);
return 0;
}
// 情况2:
// 如果进程已经在某一个 CPU 的可运行队列中
// 那么需要将进程从之前的 CPU 可运行队列中迁移到新的 CPU 可运行队列中
// 这个迁移过程由 migration_thread 内核线程完成
// 构建进程迁移请求
init_completion(&req->done);
req->task = p;
req->dest_cpu = dest_cpu;
list_add(&req->list, &rq->migration_queue);
return 1;
}
我们先来介绍一下 migrate_task 函数各个参数的意义:
p:要设置 CPU 亲和性的进程描述符。dest_cpu:绑定的 CPU 编号。req:进程迁移请求对象(下面会介绍)。
所以,migrate_task 函数的作用就是将进程描述符为 p 的进程绑定到编号为 dest_cpu 的目标 CPU 上。
migrate_task 函数主要分两种情况来将进程绑定到某个 CPU 上:
情况1:如果进程还没有在任何 CPU 的可运行队列中(不可运行状态),那么只需要将进程描述符的 cpu字段设置为dest_cpu即可。当进程变为可运行时,会根据进程描述符的cpu字段来自动放置到对应的 CPU 可运行队列中。情况2:如果进程已经在某个 CPU 的可运行队列中,那么需要将进程从之前的 CPU 可运行队列中迁移到新的 CPU 可运行队列中。迁移过程由 migration_thread内核线程完成,migrate_task函数只是构建一个进程迁移请求,并通知migration_thread内核线程有新的迁移请求需要处理。
而进程迁移过程由 __migrate_task 函数完成,我们来看看 __migrate_task 函数的实现:
static int
__migrate_task(struct task_struct *p, int src_cpu, int dest_cpu)
{
struct rq *rq_dest, *rq_src;
int ret = 0, on_rq;
...
rq_src = cpu_rq(src_cpu); // 进程所在的原可运行队列
rq_dest = cpu_rq(dest_cpu); // 进程希望放置的目标可运行队列
...
on_rq = p->se.on_rq; // 进程是否在可运行队列中(可运行状态)
if (on_rq)
deactivate_task(rq_src, p, 0); // 把进程从原来的可运行队列中删除
set_task_cpu(p, dest_cpu);
if (on_rq) {
activate_task(rq_dest, p, 0); // 把进程放置到目标可运行队列中
...
}
...
return ret;
}
__migrate_task 函数主要完成以下两个工作:
把进程从原来的可运行队列中删除。 把进程放置到目标可运行队列中。
其工作过程如下图所示(将进程从 CPU0 的可运行队列迁移到 CPU3 的可运行队列中):
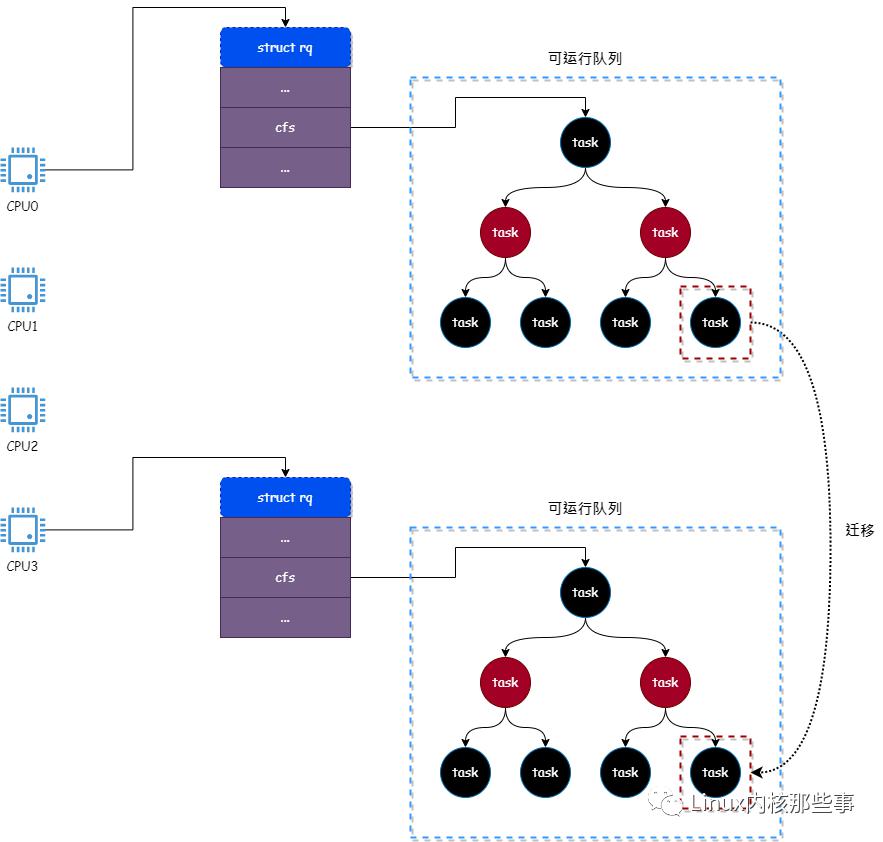
如上图所示,进程原本在 CPU0 的可运行队列中,但由于重新将进程绑定到 CPU3,所以需要将进程从 CPU0 的可运行队列迁移到 CPU3 的可运行中。
迁移过程首先将进程从 CPU0 的可运行队列中删除,然后再将进程插入到 CPU3 的可运行队列中。
当 CPU 要运行进程时,首先从它所属的可运行队列中挑选一个进程,并将此进程调度到 CPU 中运行。
总结
从上面的分析可知,其实将进程绑定到某个 CPU 只是将进程放置到 CPU 的可运行队列中。
由于每个 CPU 都有一个可运行队列,所以就有可能会出现 CPU 间可运行队列负载不均衡问题。如 CPU0 可运行队列中的进程比 CPU1 可运行队列多非常多,从而导致 CPU0 的负载非常高,而 CPU1 负载非常低的情况。
当出现上述情况时,就需要对 CPU 间的可运行队列进行重平衡操作,有兴趣的可以自行阅读源码或参考相关资料。