
hi,大家好,欢迎来到极客重生的世界,今天给大家分享的是Linux 网络新技术,当前正流行网络技是什么?那就是eBPF和XDP技术,Cilium+eBPF超级火热,Google GCP也刚刚全面转过来。
新技术出现的历史原因
廉颇老矣,尚能饭否
iptables/netfilter
iptables/netfilter 是上个时代Linux网络提供的优秀的防火墙技术,扩展性强,能够满足当时大部分网络应用需求,如果不知道iptables/netfilter是什么,请参考之前文章:一个奇葩的网络问题,把技术砖家"搞蒙了" ,里面对iptables/netfilter技术有详细介绍。
但该框架也存在很多明显问题:
路径太长
netfilter 框架在IP层,报文需要经过链路层,IP层才能被处理,如果是需要丢弃报文,会白白浪费很多CPU资源,影响整体性能;
O(N)匹配
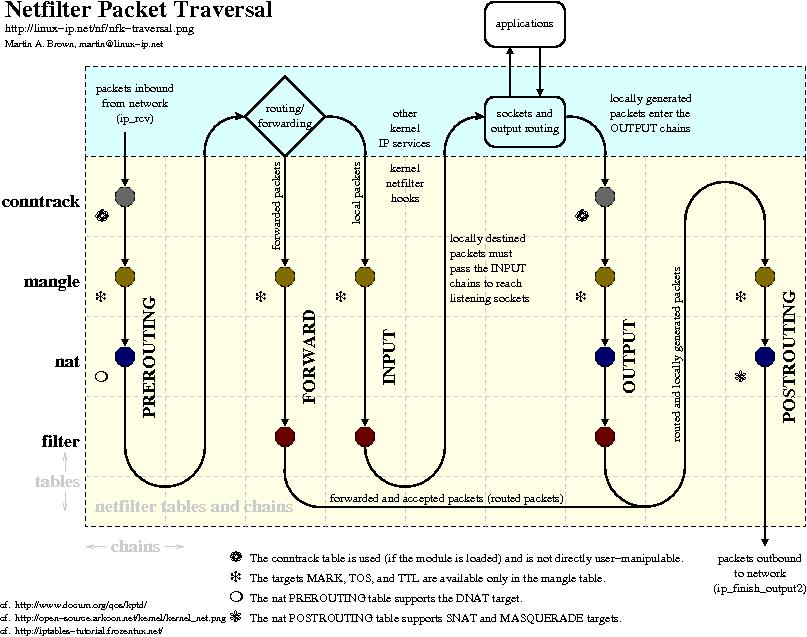
如上图所示,极端情况下,报文需要依次遍历所有规则,才能匹配中,极大影响报文处理性能;
规则太多
netfilter 框架类似一套可以自由添加策略规则专家系统,并没有对添加规则进行合并优化,这些都严重依赖操作人员技术水平,随着规模的增大,规则数量n成指数级增长,而报文处理又是0(n)复杂度,最终性能会直线下降。
内核协议栈
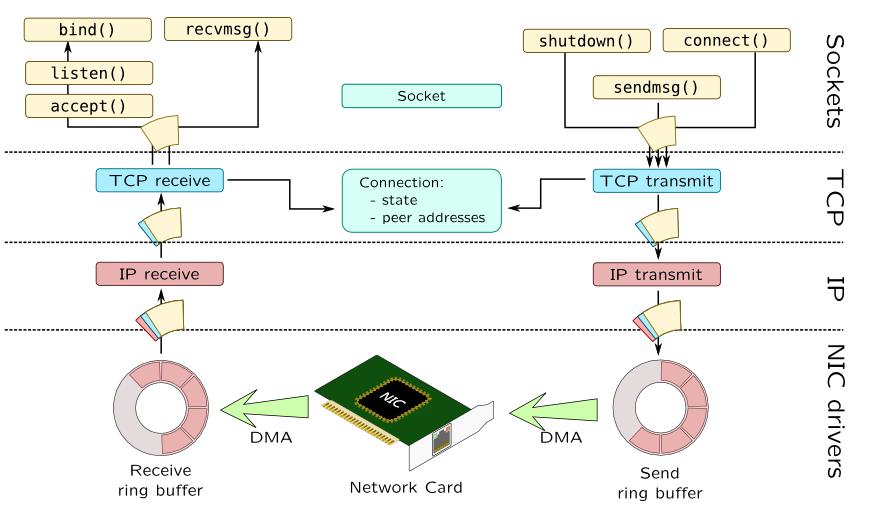
随着互联网流量越来愈大, 网卡性能越来越强,Linux内核协议栈在10Mbps/100Mbps网卡的慢速时代是没有任何问题的,那个时候应用程序大部分时间在等网卡送上来数据。
现在到了1000Mbps/10Gbps/40Gbps网卡的时代,数据被很快地收入,协议栈复杂处理逻辑,效率捉襟见肘,把大量报文堵在内核里。
各类链表在多CPU环境下的同步开销。
不可睡眠的软中断路径过长。
sk_buff的分配和释放。
内存拷贝的开销。
上下文切换造成的cache miss。
…
于是,内核协议栈各种优化措施应着需求而来:
网卡RSS,多队列。
中断线程化。
分割锁粒度。
Busypoll。
…
但却都是见招拆招,治标不治本。问题的根源不是这些机制需要优化,而是这些机制需要推倒重构。蒸汽机车刚出来的时候,马车夫为了保持竞争优势,不是去换一匹昂贵的快马,而是卖掉马去买一台蒸汽机装上。基本就是这个意思。
重构的思路很显然有两个:
upload方法:别让应用程序等内核了,让应用程序自己去网卡直接拉数据。
offload方法:别让内核处理网络逻辑了,让网卡自己处理。
总之,绕过内核就对了,内核协议栈背负太多历史包袱。
DPDK让用户态程序直接处理网络流,bypass掉内核,使用独立的CPU专门干这个事。
XDP让灌入网卡的eBPF程序直接处理网络流,bypass掉内核,使用网卡NPU专门干这个事。
如此一来,内核协议栈就不再参与数据平面的事了,留下来专门处理诸如路由协议,远程登录等控制平面和管理平面的数据流。
改善iptables/netfilter的规模瓶颈,提高Linux内核协议栈IO性能,内核需要提供新解决方案,那就是eBPF/XDP框架,让我们来看一看,这套框架是如何解决问题的。
eBPF到底是什么?
eBPF的历史
BPF 是 Linux 内核中高度灵活和高效的类似虚拟机的技术,允许以安全的方式在各个挂钩点执行字节码。它用于许多 Linux 内核子系统,最突出的是网络、跟踪和安全(例如沙箱)。
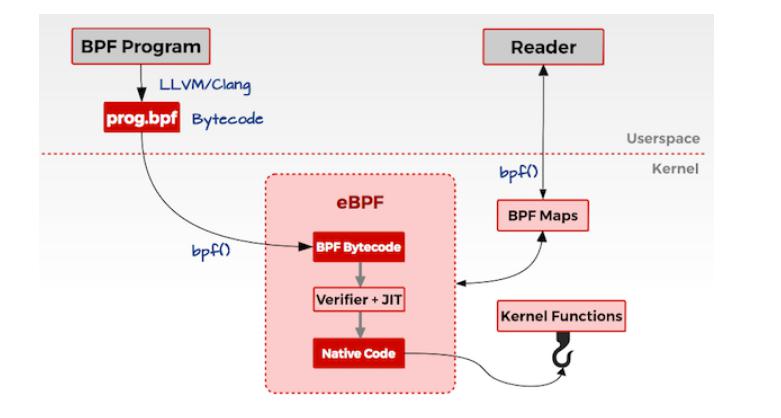
BPF架构
BPF 是一个通用目的 RISC 指令集,其最初的设计目标是:用 C 语言的一个子集编 写程序,然后用一个编译器后端(例如 LLVM)将其编译成 BPF 指令,稍后内核再通 过一个位于内核中的(in-kernel)即时编译器(JIT Compiler)将 BPF 指令映射成处理器的原生指令(opcode ),以取得在内核中的最佳执行性能。
BPF指令
尽管 BPF 自 1992 年就存在,扩展的 Berkeley Packet Filter (eBPF) 版本首次出现在 Kernel3.18中,如今被称为“经典”BPF (cBPF) 的版本已过时。许多人都知道 cBPF是tcpdump使用的数据包过滤语言。现在Linux内核只运行 eBPF,并且加载的 cBPF 字节码在程序执行之前被透明地转换为内核中的eBPF表示。除非指出 eBPF 和 cBPF 之间的明确区别,一般现在说的BPF就是指eBPF。
eBPF总体设计

BPF 不仅通过提供其指令集来定义自己,而且还通过提供围绕它的进一步基础设施,例如充当高效键/值存储的映射、与内核功能交互并利用内核功能的辅助函数、调用其他 BPF 程序的尾调用、安全加固原语、用于固定对象(地图、程序)的伪文件系统,以及允许将 BPF 卸载到网卡的基础设施。
LLVM 提供了一个 BPF后端,因此可以使用像 clang 这样的工具将 C 编译成 BPF 目标文件,然后可以将其加载到内核中。BPF与Linux 内核紧密相连,允许在不牺牲本机内核性能的情况下实现完全可编程。
eBPF总体设计包括以下几个部分:
eBPF Runtime
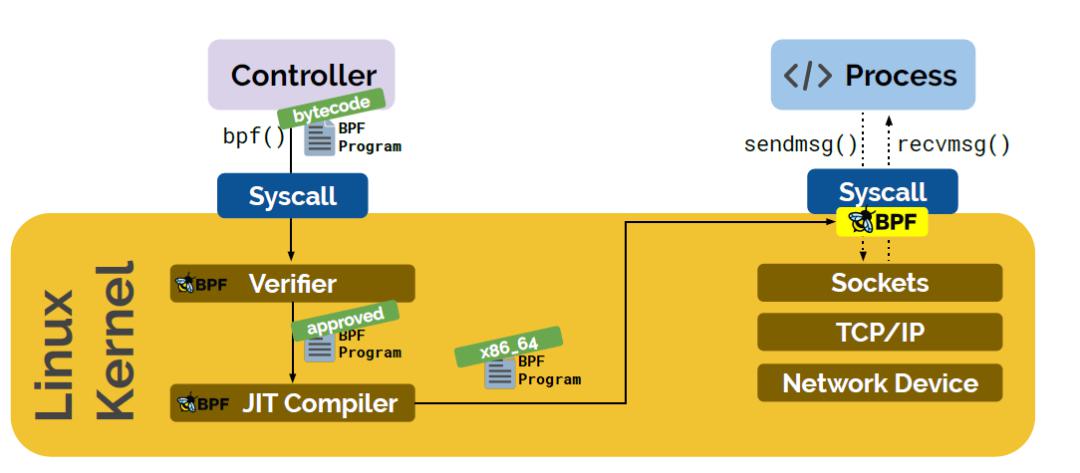
安全保障 : eBPF的verifier 将拒绝任何不安全的程序并提供沙箱运行环境
持续交付: 程序可以更新在不中断工作负载的情况下
高性能:JIT编译器可以保证运行性能
eBPF Hooks
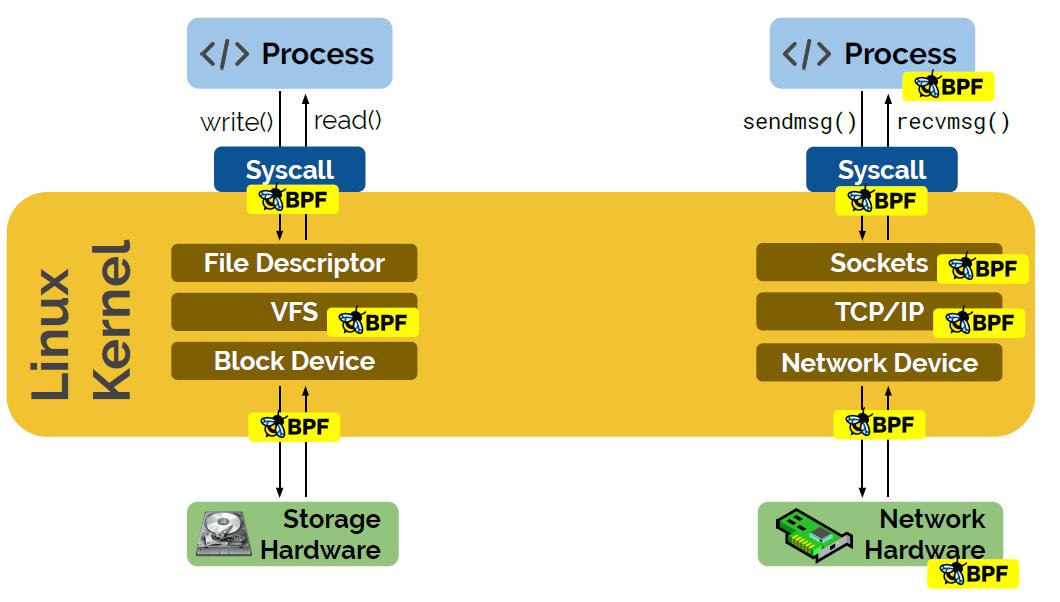
内核函数 (kprobes)、用户空间函数 (uprobes)、系统调用、fentry/fexit、跟踪点、网络设备 (tc/xdp)、网络路由、TCP 拥塞算法、套接字(数据面)
eBPF Maps
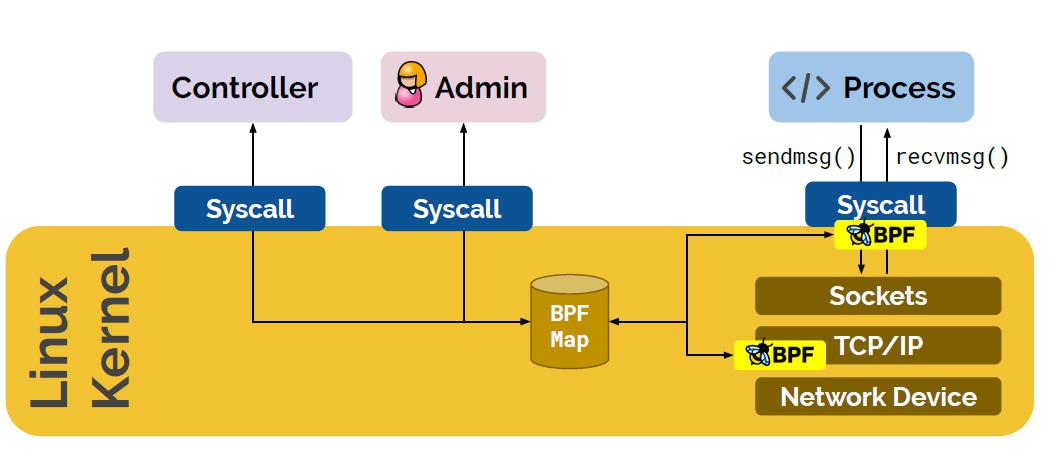
Map 类型
- Hash tables, Arrays
- LRU (Least Recently Used)
- Ring Buffer
- Stack Trace
- LPM (Longest Prefix match)
作用
程序状态
程序配置
程序间共享数据
和用户空间共享状态、指标和统计
eBPF Helpers
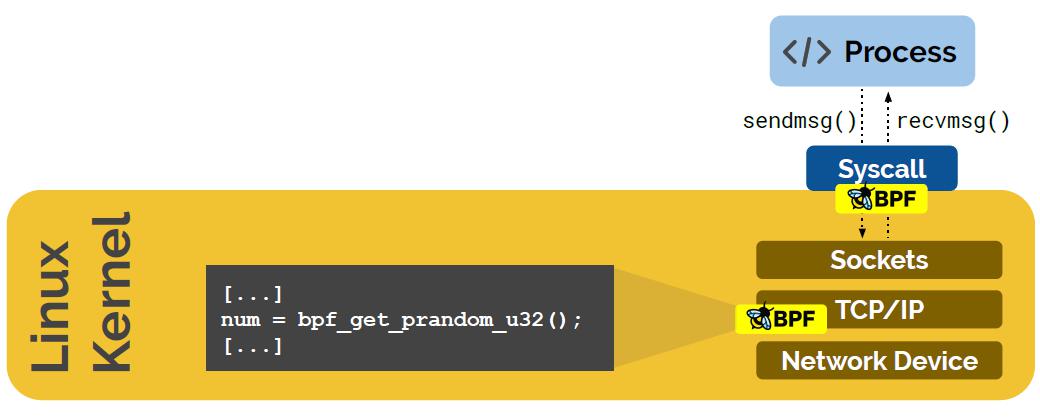
有哪些Helpers?
随机数
获取当前时间
map访问
获取进程/cgroup 上下文
处理网络数据包和转发
访问套接字数据
执行尾调用
访问进程栈
访问系统调用参数
...
eBPF Tail and Function Calls
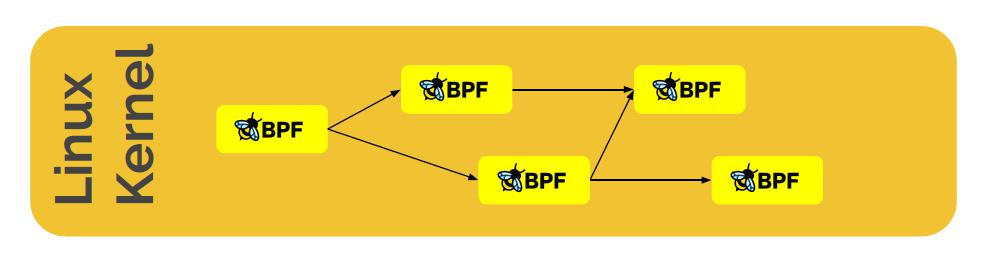
尾调用有什么用?
● 将程序链接在一起
● 将程序拆分为独立的逻辑组件
● 使 BPF 程序可组合
函数调用有什么用?
● 重用内部的功能程序
● 减少程序大小(避免内联)
eBPF JIT Compiler
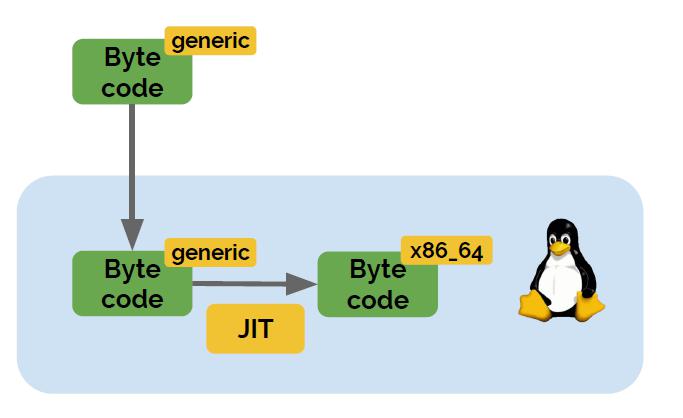
确保本地执行性能而不需要了解CPU
将 BPF字节码编译到CPU架构特定指令集
eBPF可以做什么?

eBPF 开源 Projects

Cilium

Cilium 是开源软件,用于Linux容器管理平台(如 Docker 和 Kubernetes)部署的服务之间的透明通信和提供安全隔离保护。
Cilium基于微服务的应用,使用HTTP、gRPC、Kafka等轻量级协议API相互通信。

Cilium 的基于 eBPF 的新 Linux 内核技术,它能够在 Linux 本身中动态插入强大的安全可见性和控制逻辑。由于 eBPF 在 Linux 内核中运行,因此可以在不更改应用程序代码或容器配置的情况下应用和更新 Cilium 安全策略。
Cilium在它的 datapath 中重度使用了 BPF 技术
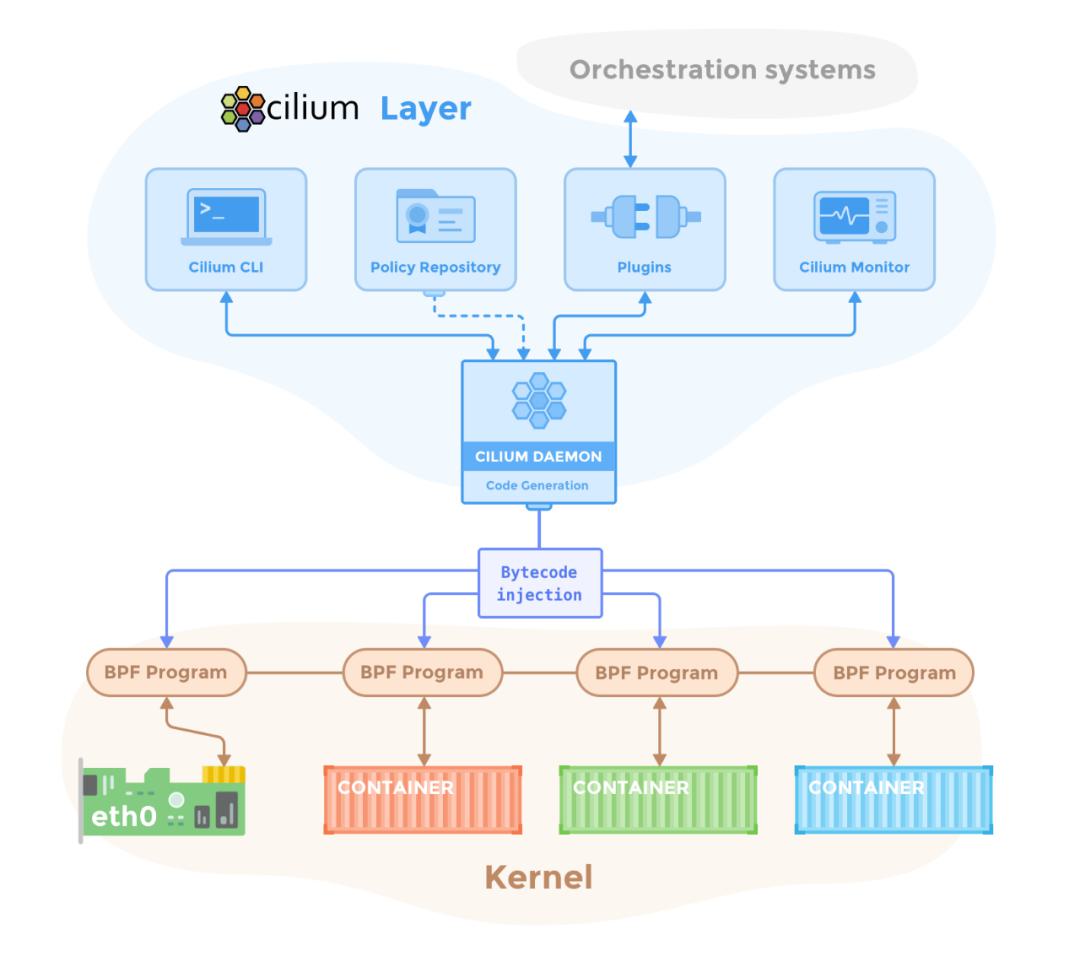
Cilium 是位于 Linux kernel 与容器编排系统的中间层。向上可以为容器配置网络,向下可以向 Linux 内核生成 BPF 程序来控制容器的安全性和转发行为。
利用 Linux BPF,Cilium 保留了透明地插入安全可视性 + 强制执行的能力,但这种方式基于服务 /pod/ 容器标识(与传统系统中的 IP 地址识别相反),并且可以根据应用层进行过滤 (例如 HTTP)。因此,通过将安全性与寻址分离,Cilium 不仅可以在高度动态的环境中应用安全策略,而且除了提供传统的第 3 层和第 4 层分割之外,还可以通过在 HTTP 层运行来提供更强的安全隔离。
BPF 的使用使得 Cilium 能够以高度可扩展的方式实现以上功能,即使对于大规模环境也不例外。
对比传统容器网络(采用iptables/netfilter):
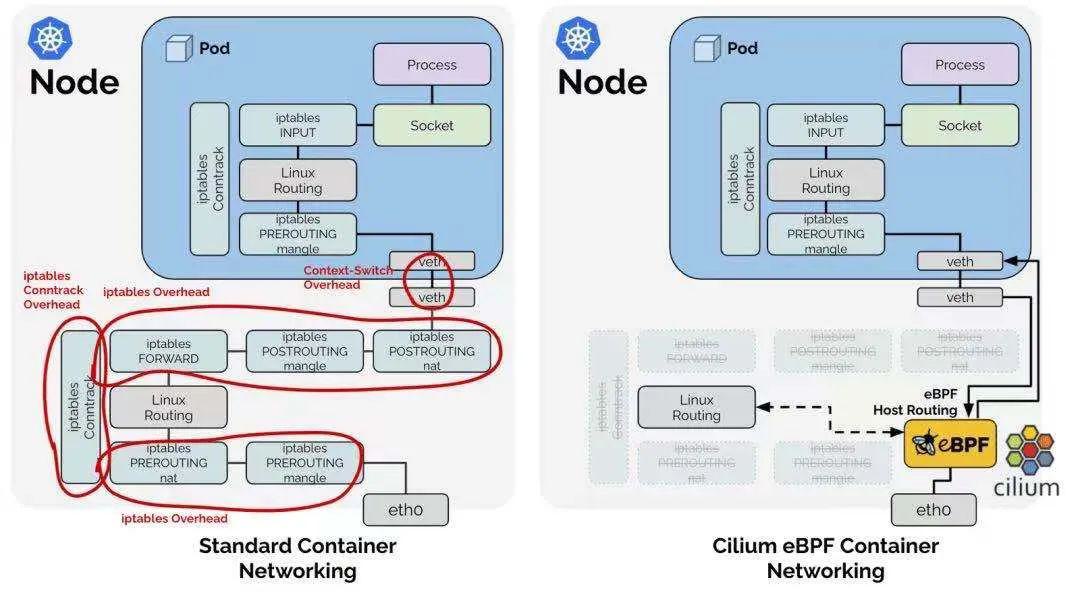
eBPF主机路由允许绕过主机命名空间中所有的 iptables 和上层网络栈,以及穿过Veth对时的一些上下文切换,以节省资源开销。网络数据包到达网络接口设备时就被尽早捕获,并直接传送到Kubernetes Pod的网络命名空间中。在流量出口侧,数据包同样穿过Veth对,被eBPF捕获后,直接被传送到外部网络接口上。eBPF直接查询路由表,因此这种优化完全透明。
基于eBPF中的kube-proxy网络技术正在替换基于iptables的kube-proxy技术,与Kubernetes中的原始kube-proxy相比,eBPF中的kuber-proxy替代方案具有一系列重要优势,例如更出色的性能、可靠性以及可调试性等等。
BCC(BPF Compiler Collection)
BCC 是一个框架,它使用户能够编写嵌入其中的 eBPF 程序的 Python 程序。该框架主要针对涉及应用程序和系统分析/跟踪的用例,其中 eBPF 程序用于收集统计信息或生成事件,用户空间中的对应部分收集数据并以人类可读的形式显示。运行 python 程序将生成 eBPF 字节码并将其加载到内核中。
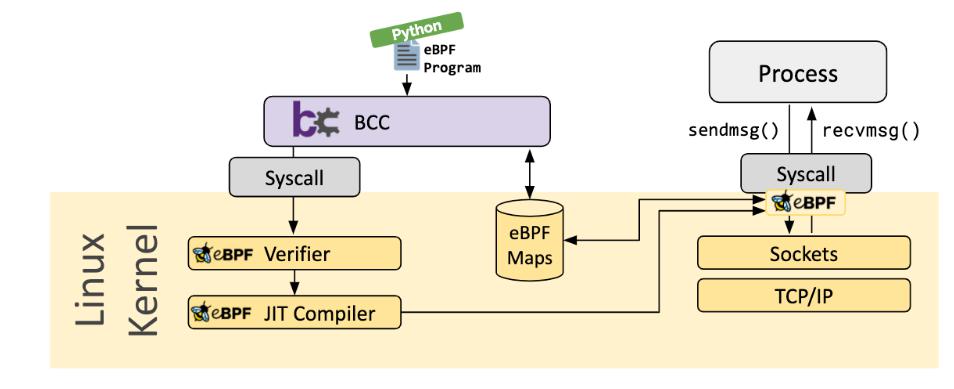
bpftrace
bpftrace 是一种用于 Linux eBPF 的高级跟踪语言,可在最近的 Linux 内核 (4.x) 中使用。bpftrace 使用 LLVM 作为后端将脚本编译为 eBPF 字节码,并利用 BCC 与 Linux eBPF 子系统以及现有的 Linux 跟踪功能进行交互:内核动态跟踪 (kprobes)、用户级动态跟踪 (uprobes) 和跟踪点. bpftrace 语言的灵感来自 awk、C 和前身跟踪器,例如 DTrace 和 SystemTap。

eBPF Go 库
eBPF Go 库提供了一个通用的 eBPF 库,它将获取 eBPF 字节码的过程与 eBPF 程序的加载和管理解耦。eBPF 程序通常是通过编写高级语言创建的,然后使用 clang/LLVM 编译器编译为 eBPF 字节码。

libbpf C/C++ 库
libbpf 库是一个基于 C/C++ 的通用 eBPF 库,它有助于解耦从 clang/LLVM 编译器生成的 eBPF 目标文件加载到内核中,并通过提供易于使用的库 API 来抽象与 BPF 系统调用的交互应用程序。

那XDP又是什么?
XDP的全称是: eXpress Data Path
XDP 是Linux 内核中提供高性能、可编程的网络数据包处理框架。
XDP整体框架
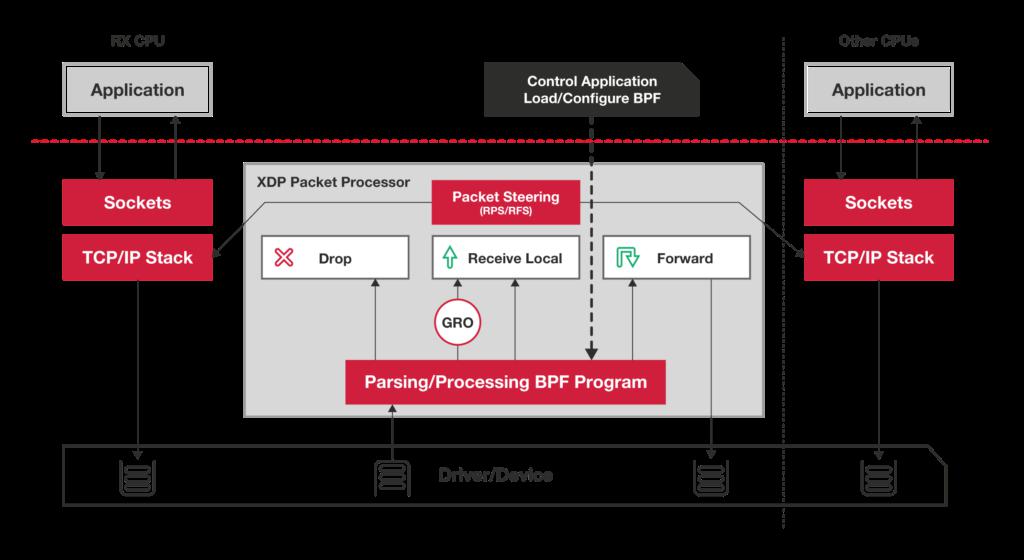
直接接管网卡的RX数据包(类似DPDK用户态驱动)处理;
通过运行BPF指令快速处理报文;
和Linux协议栈无缝对接;
XDP总体设计
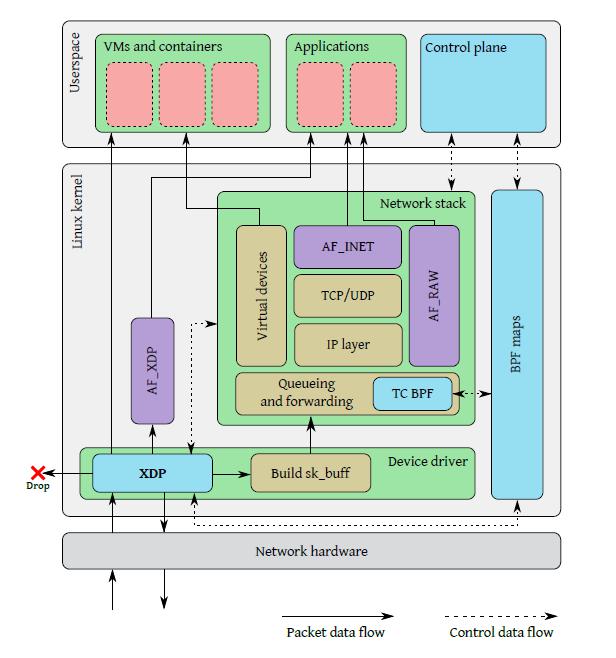
XDP总体设计包括以下几个部分:
XDP驱动
网卡驱动中XDP程序的一个挂载点,每当网卡接收到一个数据包就会执行这个XDP程序;XDP程序可以对数据包进行逐层解析、按规则进行过滤,或者对数据包进行封装或者解封装,修改字段对数据包进行转发等;
BPF虚拟机
并没有在图里画出来,一个XDP程序首先是由用户编写用受限制的C语言编写的,然后通过clang前端编译生成BPF字节码,字节码加载到内核之后运行在eBPF虚拟机上,虚拟机通过即时编译将XDP字节码编译成底层二进制指令;eBPF虚拟机支持XDP程序的动态加载和卸载;
BPF maps
存储键值对,作为用户态程序和内核态XDP程序、内核态XDP程序之间的通信媒介,类似于进程间通信的共享内存访问;用户态程序可以在BPF映射中预定义规则,XDP程序匹配映射中的规则对数据包进行过滤等;XDP程序将数据包统计信息存入BPF映射,用户态程序可访问BPF映射获取数据包统计信息;
BPF程序校验器
XDP程序肯定是我们自己编写的,那么如何确保XDP程序加载到内核之后不会导致内核崩溃或者带来其他的安全问题呢?程序校验器就是在将XDP字节码加载到内核之前对字节码进行安全检查,比如判断是否有循环,程序长度是否超过限制,程序内存访问是否越界,程序是否包含不可达的指令;
XDP Action
XDP用于报文的处理,支持如下action:
enum xdp_action {XDP_ABORTED = 0,XDP_DROP,XDP_PASS,XDP_TX,XDP_REDIRECT,};
XDP_DROP:在驱动层丢弃报文,通常用于实现DDos或防火墙
XDP_PASS:允许报文上送到内核网络栈,同时处理该报文的CPU会分配并填充一个skb,将其传递到GRO引擎。之后的处理与没有XDP程序的过程相同。
XDP_TX:从当前网卡发送出去。
XDP_REDIRECT:从其他网卡发送出去。
XDP_ABORTED:表示程序产生了异常,其行为和 XDP_DROP相同,但 XDP_ABORTED 会经过 trace_xdp_exception tracepoint,因此可以通过 tracing 工具来监控这种非正常行为。
AF_XDP
AF_XDP 是为高性能数据包处理而优化的地址族,AF_XDP 套接字使 XDP 程序可以将帧重定向到用户空间应用程序中的内存缓冲区。
XDP设计原则
XDP 专为高性能而设计。它使用已知技术并应用选择性约束来实现性能目标
XDP 还具有可编程性。无需修改内核即可即时实现新功能
XDP 不是内核旁路。它是内核协议栈的快速路径
XDP 不替代TCP/IP 协议栈。与协议栈协同工作
XDP 不需要任何专门的硬件。它支持网络硬件的少即是多原则
XDP技术优势
及时处理
在网络协议栈前处理,由于 XDP 位于整个 Linux 内核网络软件栈的底部,能够非常早地识别并丢弃攻击报文,具有很高的性能。可以改善 iptables 协议栈丢包的性能瓶颈
DDIO
Packeting steering
轮询式
高性能优化
无锁设计
批量I/O操作
不需要分配skbuff
支持网络卸载
支持网卡RSS
指令虚拟机
规则优化,编译成精简指令,快速执行
支持热更新,可以动态扩展内核功能
易编程-高级语言也可以间接在内核运行
安全可靠,BPF程序先校验后执行,XDP程序没有循环
可扩展模型
支持应用处理(如应用层协议GRO)
支持将BPF程序卸载到网卡
BPF程序可以移植到用户空间或其他操作系统
可编程性
包检测,BPF程序发现的动作
灵活(无循环)协议头解析
可能由于流查找而有状态
简单的包字段重写(encap/decap)
XDP 工作模式
XDP 有三种工作模式,默认是 native(原生)模式,当讨论 XDP 时通常隐含的都是指这 种模式。
Native XDP
默认模式,在这种模式中,XDP BPF 程序直接运行在网络驱动的早期接收路径上( early receive path)。
Offloaded XDP
在这种模式中,XDP BPF程序直接 offload 到网卡。
Generic XDP
对于还没有实现 native 或 offloaded XDP 的驱动,内核提供了一个 generic XDP 选 项,这种设置主要面向的是用内核的 XDP API 来编写和测试程序的开发者,对于在生产环境使用XDP,推荐要么选择native要么选择offloaded模式。
XDP vs DPDK
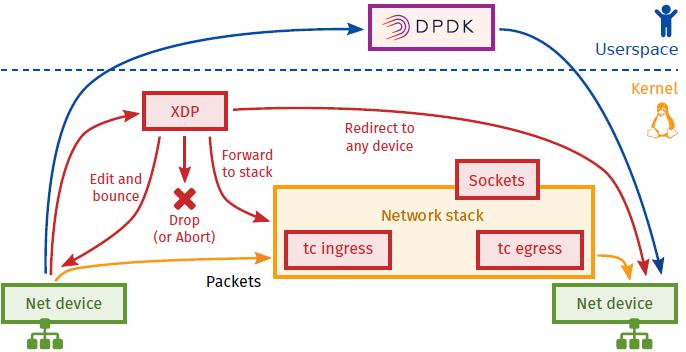
相对于DPDK,XDP:
优点
无需第三方代码库和许可
同时支持轮询式和中断式网络
无需分配大页
无需专用的CPU
无需定义新的安全网络模型
缺点
注意XDP的性能提升是有代价的,它牺牲了通用型和公平性
XDP不提供缓存队列(qdisc),TX设备太慢时直接丢包,因而不要在RX比TX快的设备上使用XDP
XDP程序是专用的,不具备网络协议栈的通用性
如何选择?
内核延伸项目,不想bypass内核的下一代高性能方案;
想直接重用内核代码;
不支持DPDK程序环境;
XDP适合场景
DDoS防御
防火墙
基于XDP_TX的负载均衡
网络统计
流量监控
栈前过滤/处理
...
XDP例子
下面是一个最小的完整 XDP 程序,实现丢弃包的功能(xdp-example.c):
#include <linux/bpf.h>
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
__section("prog")
int xdp_drop(struct xdp_md *ctx)
{
return XDP_DROP;
}
char __license[] __section("license") = "GPL";
用下面的命令编译并加载到内核:
$ clang -O2 -Wall -target bpf -c xdp-example.c -o xdp-example.o
$ ip link set dev em1 xdp obj xdp-example.o
以上命令将一个 XDP 程序 attach 到一个网络设备,需要是 Linux 4.11 内核中支持 XDP 的设备,或者 4.12+ 版本的内核。
最后
eBPF/XDP 作为Linux网络革新技术正在悄悄改变着Linux网络发展模式。
eBPF正在将Linux内核转变为微内核,越来越多的新内核功能采用eBPF实现,让新增内核功能更加快捷高效。
总体而言,基于业界基准测试结果,eBPF 显然是解决具有挑战性的云原生需求的最佳技术。
参考&延伸阅读
The eXpress Data Path:
Fast Programmable Packet Processing in the Operating System Kernel
https://docs.cilium.io/en/v1.6/bpf/
bpf-rethinkingthelinuxkernel-200303183208
https://ebpf.io/what-is-ebpf/
https://www.kernel.org/doc/html/latest/networking/af_xdp.html
https://cilium.io/blog/2021/05/11/cni-benchmark
https://blog.csdn.net/dog250/article/details/107243696
- END -
看完一键三连在看,转发,点赞
是对文章最大的赞赏,极客重生感谢你
