
本文基于 Linux-2.4.16 内核版本
由于计算机的物理内存是有限的, 而进程对内存的使用是不确定的, 所以物理内存总有用完的可能性. 那么当系统的物理内存不足时, Linux内核使用什么方案来避免申请不到物理内存这个问题呢?
相对于内存来说, 磁盘的容量是非常大的, 所以Linux内核实现了一个叫 内存交换 的功能 -- 把某些进程的一些暂时用不到的内存页保存到磁盘中, 然后把物理内存页分配给更紧急的用户使用, 当进程用到时再从磁盘读回到内存中即可. 有了 内存交换 功能, 系统可使用的内存就可以远远大于物理内存的容量.
LRU算法
内存交换 过程首先是找到一个合适的用户进程内存管理结构,然后把进程占用的内存页交换到磁盘中,并断开虚拟内存与物理内存的映射,最后释放进程占用的内存页。由于涉及到IO操作,所以这是一个比较耗时的过程。如果被交换出去的内存页刚好又被访问了,这时又需要从磁盘中把内存页的数据交换到内存中。所以,在这种情况下不单不能解决内存紧缺的问题,而且增加了系统的负荷。
为了解决这个问题,Linux内核使用了一种称为 LRU (Least Recently Used) 的算法, 下面介绍一下 LRU算法 的大体过程.
LRU 的中文翻译是 最近最少使用, 顾名思义就是一段时间内没有被使用, 那么Linux内核怎么知道哪些内存页面最近没有被使用呢? 最简单的方法就是把内存页放进一个队列里, 如果内存页被访问了, 就把内存页移动到链表的头部, 这样没被访问的内存页在一段时间后便会移动到队列的尾部, 而释放内存页时从链表的尾部开始. 著名的缓存服务器 memcached 就是使用这种 LRU算法.
Linux内核也使用了类似的算法, 但相对要复杂一些. Linux内核维护着三个队列: 活跃队列, 非活跃脏队列和非活跃干净队列. 为什么Linux需要维护三个队列, 而不是使用一个队列呢? 这是因为Linux希望内存页交换过程慢慢进行, Linux内核有个内核线程 kswapd 会定时检查系统的空闲内存页是否紧缺, 如果系统的空闲内存页紧缺时时, 就会选择一些用户进程把其占用的内存页添加到活跃链表中并断开进程与此内存页的映射关系. 随着时间的推移, 如果内存页没有被访问, 那么就会被移动到非活跃脏链表. 非活跃脏链表中的内存页是需要被交换到磁盘的, 当系统中空闲内存页紧缺时就会从非活跃脏链表的尾部开始把内存页刷新到磁盘中, 然后移动到非活跃干净链表中, 非活跃干净链表中的内存页是可以立刻分配给进程使用的. 各个链表之间的移动如下图:
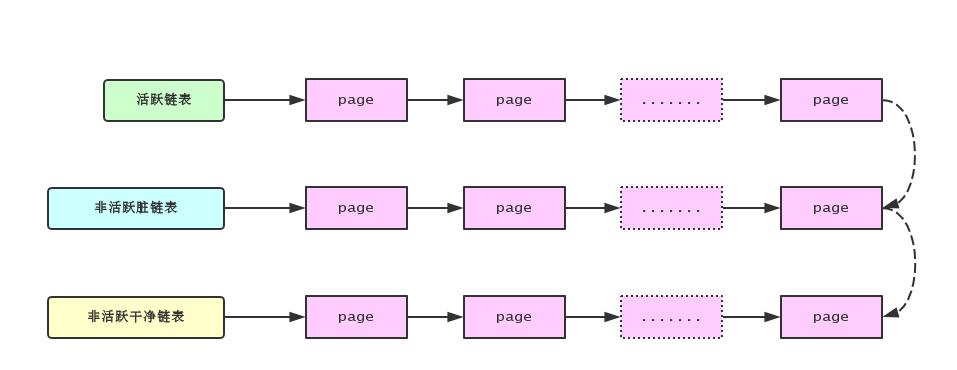
如果在这个过程中, 内存页又被访问了, 那么Linux内核会把内存页移动到活跃链表中, 并且建立内存映射关系, 这样就不需要从磁盘中读取内存页的内容.
注意: 内核只维护着一个活跃链表和一个非活跃脏链表, 但是非活跃干净链表是每个内存管理区都有一个的.
这是因为分配内存是在内存管理区的基础上进行的, 所以一个内存页必须属于某一个内存管理区.
kswapd内核线程
在Linux系统启动时会调用 kswapd_init() 函数, 代码如下:
static int __init kswapd_init(void)
{
printk("Starting kswapd v1.8\n");
swap_setup();
kernel_thread(kswapd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
kernel_thread(kreclaimd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
return 0;
}
可以看到, kswapd_init() 函数会创建 kswapd 和 kreclaimd 两个内核线程, 这两个内核线程负责在系统物理内存紧缺时释放一些物理内存页, 从而使系统的可用内存达到一个平衡. 下面我们重点来分析 kswapd 这个内核线程, kswapd() 的源码如下:
int kswapd(void *unused)
{
struct task_struct *tsk = current;
tsk->session = 1;
tsk->pgrp = 1;
strcpy(tsk->comm, "kswapd");
sigfillset(&tsk->blocked);
kswapd_task = tsk;
tsk->flags |= PF_MEMALLOC;
for (;;) {
static int recalc = 0;
if (inactive_shortage() || free_shortage()) {
int wait = 0;
/* Do we need to do some synchronous flushing? */
if (waitqueue_active(&kswapd_done))
wait = 1;
do_try_to_free_pages(GFP_KSWAPD, wait);
}
refill_inactive_scan(6, 0);
if (time_after(jiffies, recalc + HZ)) {
recalc = jiffies;
recalculate_vm_stats();
}
wake_up_all(&kswapd_done);
run_task_queue(&tq_disk);
if (!free_shortage() || !inactive_shortage()) {
interruptible_sleep_on_timeout(&kswapd_wait, HZ);
} else if (out_of_memory()) {
oom_kill();
}
}
}
kswapd 内核线程由一个无限循环组成, 首先通过 inactive_shortage() 和 free_shortage() 函数判断系统的非活跃页面和空闲物理内存页是否短缺, 如果短缺的话, 那么就调用 do_try_to_free_pages() 函数试图释放一些物理内存页. 然后通过调用 refill_inactive_scan() 函数把一些活跃链表中的内存页移动到非活跃脏链表中. 最后, 如果空闲物理内存页或者非活跃内存页不短缺, 那么就让 kswapd 内核线程休眠一秒.
接下来我们分析一下 do_try_to_free_pages() 函数做了一些什么工作, 代码如下:
static int do_try_to_free_pages(unsigned int gfp_mask, int user)
{
int ret = 0;
if (free_shortage() || nr_inactive_dirty_pages > nr_free_pages() + nr_inactive_clean_pages())
ret += page_launder(gfp_mask, user);
if (free_shortage() || inactive_shortage()) {
shrink_dcache_memory(6, gfp_mask);
shrink_icache_memory(6, gfp_mask);
ret += refill_inactive(gfp_mask, user);
} else {
kmem_cache_reap(gfp_mask);
ret = 1;
}
return ret;
}
do_try_to_free_pages() 函数第一步先判断系统中的空闲物理内存页是否短缺, 或者非活跃脏页面的数量大于空闲物理内存页和非活跃干净页面的总和, 其中一个条件满足了, 就调用 page_launder() 函数把非活跃脏链表中的页面刷到磁盘中, 然后移动到非活跃干净链表中. 接下来如果内存还是紧缺的话, 那么就调用 shrink_dcache_memory(), shrink_icache_memory() 和 refill_inactive() 函数继续释放内存.
下面我们先来分析一下 page_launder() 这个函数, 由于这个函数很长, 所以我们分段来解释:
int page_launder(int gfp_mask, int sync)
{
int launder_loop, maxscan, cleaned_pages, maxlaunder;
int can_get_io_locks;
struct list_head * page_lru;
struct page * page;
can_get_io_locks = gfp_mask & __GFP_IO; // 是否需要进行写盘操作
launder_loop = 0;
maxlaunder = 0;
cleaned_pages = 0;
dirty_page_rescan:
spin_lock(&pagemap_lru_lock);
maxscan = nr_inactive_dirty_pages;
// 从非活跃脏链表的后面开始扫描
while ((page_lru = inactive_dirty_list.prev) != &inactive_dirty_list &&
maxscan-- > 0) {
page = list_entry(page_lru, struct page, lru);
...
上面的代码首先把 pagemap_lru_lock 上锁, 然后从尾部开始遍历非活跃脏链表.
// 如果满足以下的任意一个条件, 都表示内存页在使用中, 把他移动到活跃链表
if (PageTestandClearReferenced(page) || // 如果设置了 PG_referenced 标志
page->age > 0 || // 如果age大于0, 表示页面被访问过
(!page->buffers && page_count(page) > 1) || // 如果页面被其他进程映射
page_ramdisk(page)) { // 如果用于内存磁盘的页面
del_page_from_inactive_dirty_list(page);
add_page_to_active_list(page);
continue;
}
上面代码判断内存页是否能需要重新移动到活跃链表中, 依据有:
内存页是否设置了 PG_referenced标志;内存页的age字段是否大于0 (age字段是内存页的生命周期); 内存页是否还有映射关系; 内存页是否用于内存磁盘.
如果满足上面其中一个条件, 都需要重新把内存页移动到活跃页面中.
if (PageDirty(page)) { // 如果页面是脏的, 那么应该把页面写到磁盘中
int (*writepage)(struct page *) = page->mapping->a_ops->writepage;
int result;
if (!writepage)
goto page_active;
/* First time through? Move it to the back of the list */
if (!launder_loop) { // 第一次只把页面移动到链表的头部, 这是为了先处理已经干净的页面
list_del(page_lru);
list_add(page_lru, &inactive_dirty_list);
UnlockPage(page);
continue;
}
/* OK, do a physical asynchronous write to swap. */
ClearPageDirty(page);
page_cache_get(page);
spin_unlock(&pagemap_lru_lock);
result = writepage(page);
page_cache_release(page);
/* And re-start the thing.. */
spin_lock(&pagemap_lru_lock);
if (result != 1)
continue;
/* writepage refused to do anything */
set_page_dirty(page);
goto page_active;
}
上面的代码首先判断内存页是否脏的(是否设置了 PG_dirty 标志), 如果是, 那么就需要把内存页刷新到磁盘中. 这里有个要主要的地方是, 当 launder_loop 变量为0时只是把内存页移动到非活跃脏链表的头部. 当 launder_loop 变量为1时才会把内存页刷新到磁盘中. 为什么要这样做呢? 这是因为Linux内核希望第一次扫描先把非活跃脏链表中的干净内存页移动到非活跃干净链表中, 第二次扫描才把脏的内存页刷新到磁盘中. 后面的代码会对 launder_loop 变量进行修改. 而且我们发现, 把脏页面刷新到磁盘后, 并没有立刻把内存页移动到非活跃干净链表中, 而是简单的清除了 PG_dirty 标志.
if (page->buffers) { // 涉及文件系统部分, 先略过
...
} else if (page->mapping && !PageDirty(page)) { // 内存页是干净的, 移动到非活跃干净链表
del_page_from_inactive_dirty_list(page);
add_page_to_inactive_clean_list(page);
UnlockPage(page);
cleaned_pages++;
} else {
page_active:
del_page_from_inactive_dirty_list(page);
add_page_to_active_list(page);
UnlockPage(page);
}
上面的代码比较简单, 如果内存页已经是干净的, 那么久移动到非活跃干净链表中.
if (can_get_io_locks && !launder_loop && free_shortage()) {
launder_loop = 1;
/* If we cleaned pages, never do synchronous IO. */
if (cleaned_pages)
sync = 0;
/* We only do a few "out of order" flushes. */
maxlaunder = MAX_LAUNDER;
/* Kflushd takes care of the rest. */
wakeup_bdflush(0);
goto dirty_page_rescan;
}
/* Return the number of pages moved to the inactive_clean list. */
return cleaned_pages;
}
从上面的代码可以看到, 当 can_get_io_locks 等于1(gfp_mask 设置了 __GFP_IO 标志), launder_loop 等于0, 并且空闲内存页还是短缺(free_shortage() 为真)的情况下, 把 launder_loop 变量被设置为1, 并且跳转到 dirty_page_rescan 处重新扫描, 这是第二次扫描非活跃脏链表, 会把脏的内存页刷新到磁盘中.
接下来我们继续分析 refill_inactive() 这个函数:
static int refill_inactive(unsigned int gfp_mask, int user)
{
int priority, count, start_count, made_progress;
count = inactive_shortage() + free_shortage();
if (user)
count = (1 << page_cluster);
start_count = count;
...
priority = 6;
do {
made_progress = 0;
if (current->need_resched) {
__set_current_state(TASK_RUNNING);
schedule();
}
while (refill_inactive_scan(priority, 1)) { // 把活跃页面链表中的页面移动到非活跃脏页面链表中
made_progress = 1;
if (--count <= 0)
goto done;
}
...
while (swap_out(priority, gfp_mask)) { // 把一些用户进程映射的内存页放置到活跃页面链表中
made_progress = 1;
if (--count <= 0)
goto done;
}
if (!inactive_shortage() || !free_shortage())
goto done;
if (!made_progress)
priority--;
} while (priority >= 0);
while (refill_inactive_scan(0, 1)) {
if (--count <= 0)
goto done;
}
done:
return (count < start_count);
}
在这个函数中, 我们主要关注两个地方:
调用 refill_inactive_scan()函数,refill_inactive_scan()函数的作用是把活跃链表中的内存页移动到非活跃脏链表中.调用 swap_out()函数,swap_out()函数的作用是选择一个用户进程, 并且把其映射的内存页添加到活跃链表中.
先来看看 refill_inactive_scan() 函数:
int refill_inactive_scan(unsigned int priority, int oneshot)
{
struct list_head * page_lru;
struct page * page;
int maxscan, page_active = 0;
int ret = 0;
spin_lock(&pagemap_lru_lock);
maxscan = nr_active_pages >> priority;
while (maxscan-- > 0 && (page_lru = active_list.prev) != &active_list) {
page = list_entry(page_lru, struct page, lru);
...
/* Do aging on the pages. */
if (PageTestandClearReferenced(page)) {
age_page_up_nolock(page);
page_active = 1;
} else {
age_page_down_ageonly(page); // page->age = page->age / 2
if (page->age == 0 && page_count(page) <= (page->buffers ? 2 : 1)) {
deactivate_page_nolock(page); // 把页面放置到非活跃脏页面链表
page_active = 0;
} else {
page_active = 1;
}
}
if (page_active || PageActive(page)) {
list_del(page_lru);
list_add(page_lru, &active_list);
} else {
ret = 1;
if (oneshot)
break;
}
}
spin_unlock(&pagemap_lru_lock);
return ret;
}
refill_inactive_scan() 函数比较简单, 首先从活跃链表的尾部开始遍历, 然后判断内存页的生命是否已经用完(age是否等于0), 并且没有进程与其有映射关系(count是否等于1). 如果是, 那么就调用 deactivate_page_nolock() 函数把内存页移动到非活跃脏链表中.
接着来看看 swap_out() 函数, swap_out() 函数比较复杂, 但最终会调用 try_to_swap_out() 函数, 所以我们只分析 try_to_swap_out() 函数:
static int try_to_swap_out(struct mm_struct * mm, struct vm_area_struct* vma, unsigned long address, pte_t * page_table, int gfp_mask)
{
...
page = pte_page(pte);
if (!mm->swap_cnt)
return 1;
mm->swap_cnt--;
...
if (PageSwapCache(page)) { // 内存页之前已经发生过交换操作
entry.val = page->index;
if (pte_dirty(pte))
set_page_dirty(page);
set_swap_pte:
swap_duplicate(entry);
// 把页目录项设置为磁盘交换区的信息(注意:此时是否在内存中标志位为0, 所以访问这个内存地址会触发内存访问异常)
set_pte(page_table, swp_entry_to_pte(entry));
drop_pte:
UnlockPage(page);
mm->rss--;
deactivate_page(page);
page_cache_release(page);
out_failed:
return 0;
}
...
entry = get_swap_page();
if (!entry.val)
goto out_unlock_restore; /* No swap space left */
add_to_swap_cache(page, entry);
set_page_dirty(page);
goto set_swap_pte;
out_unlock_restore:
set_pte(page_table, pte);
UnlockPage(page);
return 0;
}
上面的代码中, 首先调用 get_swap_page() 函数获取交换文件的一个槽(用于保存内存页的内容), 然后调用 add_to_swap_cache() 函数把内存页添加到活跃链表中, add_to_swap_cache() 函数源码如下:
void add_to_swap_cache(struct page *page, swp_entry_t entry)
{
...
add_to_page_cache_locked(page, &swapper_space, entry.val);
}
void add_to_page_cache_locked(struct page * page, struct address_space *mapping, unsigned long index)
{
if (!PageLocked(page))
BUG();
page_cache_get(page);
spin_lock(&pagecache_lock);
page->index = index;
add_page_to_inode_queue(mapping, page);
add_page_to_hash_queue(page, page_hash(mapping, index));
lru_cache_add(page);
spin_unlock(&pagecache_lock);
}
add_to_swap_cache() 函数会调用 add_to_page_cache_locked() 函数, 而add_to_page_cache_locked() 函数会调用 lru_cache_add() 函数来把内存页添加到活跃链表中, lru_cache_add() 函数代码如下:
#define add_page_to_active_list(page) { \
DEBUG_ADD_PAGE \
ZERO_PAGE_BUG \
SetPageActive(page); \
list_add(&(page)->lru, &active_list); \
nr_active_pages++; \
}
void lru_cache_add(struct page * page)
{
spin_lock(&pagemap_lru_lock);
if (!PageLocked(page))
BUG();
DEBUG_ADD_PAGE
add_page_to_active_list(page);
/* This should be relatively rare */
if (!page->age)
deactivate_page_nolock(page);
spin_unlock(&pagemap_lru_lock);
}
从上面的代码可以看到, lru_cache_add() 函数最终会调用 list_add(&(page)->lru, &active_list) 这行代码来把内存页添加到活跃链表(active_list)中, 并设置内存页的 PG_active 标志.
最后我们通过一幅图来总结一下 kswapd 内核线程的流程:
kswap()
└→ do_try_free_pages()
└→ page_launder()
└→ refill_inactive()
└→ refill_inactive_scan()
└→ swap_out()
swap_out() 函数会把进程占用的内存页添加到活跃链表中, 而 refill_inactive_scan() 函数会把活跃链表的内存页移动到非活跃脏链表中, 最后 page_launder() 会把非活跃脏链表的内存页刷新到磁盘并且移动到非活跃干净链表中, 非活跃干净链表中的内存页是直接可以用来分配使用的.
往期推荐