
SYSCALL
系统调用就是调用操作系统提供的一系列内核功能函数,因为内核总是对用户程序持不信任的态度,一些核心功能不能直接交由用户程序来实现执行。用户程序只能发出请求,然后内核调用相应的内核函数来帮着处理,将结果返回给应用程序。如此才能保证系统的稳定和安全。本文采用 的实例来讲解系统调用具体是如何实现的。
系统调用是给用户态下的程序使用的,但是用户程序并不直接使用系统调用,而是系统调用在用户态下的接口。这个用户接口就是操作系统提供的系统调用 ,一般遵循 标准。
的系统调用是用 INT n 指令实现的,INT n 的作用就是触发一个 号中断,中断的过程应该很熟悉了吧,不熟悉的可以看看前文:多处理器下的中断机制。 里面系统调用使用的向量号是 , 里面使用的 (不同 版本可能不同)。只要这个向量号 不是一些异常使用的,一些保留的和一些外设默认使用的,用多少来表示系统调用其实无伤大雅, 要用 ,那就 好了。
上述说的用户接口就会执行 INT 64 触发一个 号中断,这里 做了简化,按照以前版本的 ,用户接口是调用一个宏定义 ,这个宏再来执行 INT 指令触发中断。关于这部分可以看看前文:捋一捋系统调用
执行 INT 64 之后, 会根据向量号 去 中索引第 个门描述符(从 0 计数),这个门描述符中存放的有系统调用程序的偏移量和段选择子,再根据段选择子去 中索引段描述符,段描述符中记录的有段基址,与门描述符中记录的偏移量相加就是系统调用程序的地址。拿到系统调用程序的地址,就可以执行程序做相应的处理了。
可是系统调用是有很多的,虽然 中实现的系统调用没多少,没多少也还是有那么一些的,怎么区别它们呢?这就涉及了系统调用号概念,每一个系统调用都唯一分配了一个整数来标识,比如说 里面 系统调用的调用号就为 1。INT 64,表示触发一个中断向量号为 64 的中断,而这个中断表示系统调用,并没有具体说是哪一个系统调用,所以还需要一个系统调用号来表示具体的系统调用。
系统调用通俗的讲就是是用户态下的程序托内核办事,既然是托人办事那得告诉人家你要办什么事对吧。这个告诉人家具体要办什么事就是要给内核传递系统调用号,问题是怎么传呢?通常的做法就是将这个系统调用号放进 寄存器,当执行到系统调用入口程序的时候就会根据 eax 的值去调用具体的系统调用程序,比如说 中存放的是 1 那么就会去调用 这个系统调用的相关函数。这个系统调用的入口程序可以理解为在第 个门描述符中记录的程序,因为肯定是要先根据向量号拿到总的中断服务程序(在这儿就是总的系统调用程序),然后再根据 的值去调用的具体的内核功能函数。
上面只是说的一般的大致情况,如果看过前文多处理器下的中断机制应该知道, 对所有中断(包括系统调用)的处理是先执行共同的中断入口程序,主要就是保护现场压栈寄存器,然后根据向量号的不同执行不同的中断处理程序。在这里就是执行系统调用入口程序,然后再根据 的值调用具体的内核功能函数。
这个具体的内核功能函数咱们就不讨论了,内核中的表现形式就是一个个不同的函数,咱们这儿只讨论两件事:
一是参数,有些系统调用的是需要参数的,用户接口不真正干活,真正干活的是内核功能函数,但是需要的参数在用户态下,所以需要在用户接口部分向内核传递参数。传参有两种方法:
直接传给寄存器,寄存器是通用的,在用户态将值传给寄存器,进入内核态之后就可以直接使用,这可以使用内联汇编来实现。 压栈,压栈有个问题,系统调用使用中断/陷阱来实现,这期间会换栈,在用户态下压栈的参数对内核来说似乎没什么用处。所以要想使用用户态下栈中的参数,必须要获得用户栈的地址,这个值在哪呢?没错,在内核栈中的上下文保存着,从内核栈中取出用户栈的栈顶 值,就可以取到系统调用的参数了, 就是这样实现的。
二是返回值,函数的调用约定中规定了返回值应该放在 寄存器里面。而在系统调用的一开始我们将系统调用号传进了 寄存器,然后中断时保存上下文,将 压入内核栈,系统调用处理程序将最后结果放到 寄存器中。下面注意了,如果不对上下文中的 作修改的话,中断退出的时候恢复上下文弹出 ,弹出的值是啥?是系统调用号,也就是说将结果放到 寄存器中放了个寂寞,所以肯定会有一个步骤修改上下文中 为结果这么一个步骤,这样回到用户态的时候这个结果才会在 寄存器中。
上述差不多将系统调用的一些理论知识说完了,下面用 的实例来看看系统调用具体如何实现的。
xv6 实例
先来看张总图把握一下整体流程:

首先便是用户接口部分,用户接口是操作系统提供的系统调用 函数,一般是 标准, 关于这用户接口定义在 中,来随便看两个:
int fork(void);
int write(int, const void*, int);
这只是对函数原型的声明。具体做了什么事呢?这个定义在 中:
#include "syscall.h"
#include "traps.h"
#define SYSCALL(name) \
.globl name; \
name: \
movl $SYS_ ## name, %eax; \
int $T_SYSCALL; \
ret
SYSCALL(fork)
SYSCALL(write)
SYSCALL(getpid)
这是用汇编来写的,而且使用了宏定义,我们来仔细阅读一下这段代码
.global name 声明了一个全局可见的名字,可以是变量也可以是函数名,这里就与用户接口的函数名。函数名就相当于一个地址,name: 后面的代码就是这个函数具体要做的事,就像 c 语言编写函数时的函数体,只不过这里是用汇编写的而已。
所以这个函数做了什么事?应该一目了然啊,就三条指令:
movl \$SYS_ ## name, %eax将系统调用号传到寄存器int $T_SYSCALL触发 号中断ret函数返回
这里还使用了一些宏定义,首先是系统调用号,定义在 当中,随便看几个意思一下:
#define SYS_fork 1
#define SYS_getpid 11
#define SYS_write 16
这个号就是自定义的,能够将每个系统调用唯一区分开就好。
上面的宏定义中还涉及了 # 的用法,# 一般有两种用法:
#define STR(x) #x
#define CAT(x, y) x##y
一个 # 表示字符串化,如果 为 abc,则结果为 "abc"
两个 ## 表示连接符,如果 为 ab, 为 cd,则结果为 abcd
所以上述 SYS_ ## name,如果 为 ,那么结果就是 SYS_fork,表示 的系统调用号。
代表的系统调用的向量号, 版本不同,这个数可能不同,我这儿是 ,所以 int $T_SYSCALL 相当于触发了一个 号中断。
接着就应该是中断的处理过程,这一块在前文多处理器下的中断机制已经讲述的很详细了,而且还有过程图,本文就不再赘述。本文重点讲述执行了通用的中断入口程序之后如何执行系统调用分支的,如何获取用户栈的参数,如何修改上下文中的 使其返回正确的结果。
问题很多,咱们一个一个来解决,首先从 IDT, GDT 中获取到中断入口程序的地址之后,执行中断入口程序压栈寄存器来保存上下文,这个上下文中包括了向量号。
保存了上下文之后跳到 这个总的中断处理程序,这个程序中会根据向量号不同去执行不同的中断处理程序,如果向量号表示的是系统调用的话,就会进行如下操作:
void trap(struct trapframe *tf)
{
if(tf->trapno == T_SYSCALL){ //如果向量号表示的是系统调用
if(myproc()->killed)
exit();
myproc()->tf = tf; //当前进程的中断栈帧
syscall(); //执行系统调用入口程序
if(myproc()->killed)
exit();
return;
}
/*******略略略略********/
}
可以看到,如果中断栈帧中的向量号表示的是系统调用号的话,就会去执行系统调用入口程序。
这个系统调用入口程序定义在 里面:
void syscall(void)
{
int num;
struct proc *curproc = myproc(); //获取当前进程的PCB
num = curproc->tf->eax; //获取系统调用号
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
curproc->tf->eax = syscalls[num](); //调用相应的系统调用处理函数,返回值赋给eax
} else {
cprintf("%d %s: unknown sys call %d\n",
curproc->pid, curproc->name, num);
curproc->tf->eax = -1;
}
}
这个系统调用的入口函数的作用就是根据中断栈帧中的系统调用号去调用相应的内核功能函数,然后将返回值再填写到栈帧中的 处。
这个流程整个逻辑应该是很清晰的,主要注意一点,调用内核功能函数的方式:syscalls[num]() , 是系统调用号, 看形式应该是个数组,从这里其实应该就能猜出来了, 将所有具体的系统调用处理函数地址按照系统调用号的顺序集合成了一个数组。事实也的确如此,同样的来随便看几个:
extern int sys_fork(void);
extern int sys_getpid(void);
extern int sys_write(void);
static int (*syscalls[])(void) = {
[SYS_fork] sys_fork,
/**********************/
[SYS_getpid] sys_getpid,
/**********************/
[SYS_write] sys_write,
/***********************/
}
extern int sys_fork(void); 表示具体的 这个内核的功能函数,这个函数才是真正干事的,它在外面定义,所以用了 ,至于具体这个函数干了什么事,在本文不重要,本文主要事了解系统调用这个流程,后面讲述进程的时候再具体讲述这个函数,或者前面写过一篇关于 的文章:使用分身术变身术创建新进程
接下来是定义了一个函数指针数组,就是将上述函数地址填到数组相应的位置上。[SYS_fork] sys_fork 这种填充数组元素的方式似乎不太常见,但在这里就非常实用,表示将 这个函数的地址填写到索引为 的位置上去。
关于系统调用还剩下最后一个问题,根据上述内核中具体的系统调用函数原型可以看出,它们的返回类型都是 型且没有参数,但是有些系统调用是需要参数的,所以那些需要参数的系统调用就要去获取参数,去哪获取呢?是的,去用户栈获取参数,因为 没有使用寄存器来传参,而是将参数直接压入用户栈里面的。
回到系统调用的开头,何时将参数压栈的,参数是为被调用函数准备的,所以调用函数之前一定会将参数压栈。这个被调用函数就是用户接口,举个例子如果调用 ,则在这之前一定会将参数 按照这个顺序压栈,再 调用函数,只是在 语言中这个过程可能看起来不是那么真切,如果是用汇编来写,或者查看编译之后的程序,会有下面的大致过程:
push size
push buf
push fd
call write
在 call wirte 之后又会将下条指令地址压栈当作放回地址, (用户接口) 又做了三件事,传系统调用号,int T_SYSCALL, ret 返回。int T_SYSCALL 之后换栈,用户栈栈顶 保存在上下文中的 处。
捋清楚这个关系之后就知道怎么去拿参数了,直接去中断栈帧中获取用户栈栈顶值 ,再根据参数返回地址的位置关系获取一个个参数,来看 中有关获取参数的几个函数:
int argint(int n, int *ip) //获取系统调用的第n个int型的参数,存到ip这个位置
{
return fetchint((myproc()->tf->esp) + 4 + 4*n, ip); //原栈中获取n个int型参数,加4是跳过
}
int fetchint(uint addr, int *ip)
{
struct proc *curproc = myproc();
if(addr >= curproc->sz || addr+4 > curproc->sz)
return -1;
*ip = *(int*)(addr);
return 0;
}
这是获取一个 t 型的参数,(myproc()->tf->esp) + 4 + 4*n 表示第 个参数( 型) 的位置,多加了一个 是因为要跳过返回地址 字节。然后调用 ) 去取参数,核心语句就一句:*ip = *(int*)(addr); 将这个地址转化为 型再解引用放在地址 上,说着有些绕口,自己看一下应该还是很好明白的。至于这个函数中关于进程部分的一些条件检查,现下可以不予理会。
int argptr(int n, char **pp, int size)
{
int i;
struct proc *curproc = myproc();
if(argint(n, &i) < 0)
return -1;
if(size < 0 || (uint)i >= curproc->sz || (uint)i+size > curproc->sz)
return -1;
*pp = (char*)i;
return 0;
}
这个函数用来获取一个指针,指针就是地址,地址就是一个 位无符号数,所以调用前面的 来获取这个数存到 中,这个 本身其实是个地址值,所以将其转化 类型,然后赋值给 。
注意这里使用的是二级指针,为什么要使用二级指针,我们来看看如果使用一级指针会发生什么,如果这个函数是这样:
int argptr(int n, char *pp, int size) //pp类型变为char*
{
int i;
/*********************/
if(argint(n, &i) < 0)
return -1;
/*********************/
pp = (char*)i; //这里变为直接给pp赋值
return 0;
}
如果这个函数变成这样还对吗,答案是不对的。举个例子来说明,在 这个内核功能函数中会调用 :
char *p;
argptr(1, &p, n);
/**如果用一级指针**/
argptr(1, p, n);
调用 的本意是获取第一个参数,也就是用户接口 的 地址值,并将其赋给 。
假如 等于某个地址 ,如果使用一级指针:调用 argptr(1, p, n); int argptr(int n, char *pp, int size),这个 是实参, 是形参,,虽然 和 的值相等,但它们两个是两个不同的变量,所以如果修改 , 的值是不会变化的,因此使用一级指针就不对。
如果使用的是二级指针,调用 argptr(1, &p, n); int argptr(int n, char **pp, int size)。实参是 的地址, 本身就是个地址值,所以 ,修改 就是 。嗯这下就对了,所以这里要使用二级指针才对头。
还有个获取字符串的函数,跟获取指针差不了太多,只是多了一个算字符串长度的步骤,这里就不赘述了。
本文关于系统调用就这么多,最后再看张图来捋一捋:
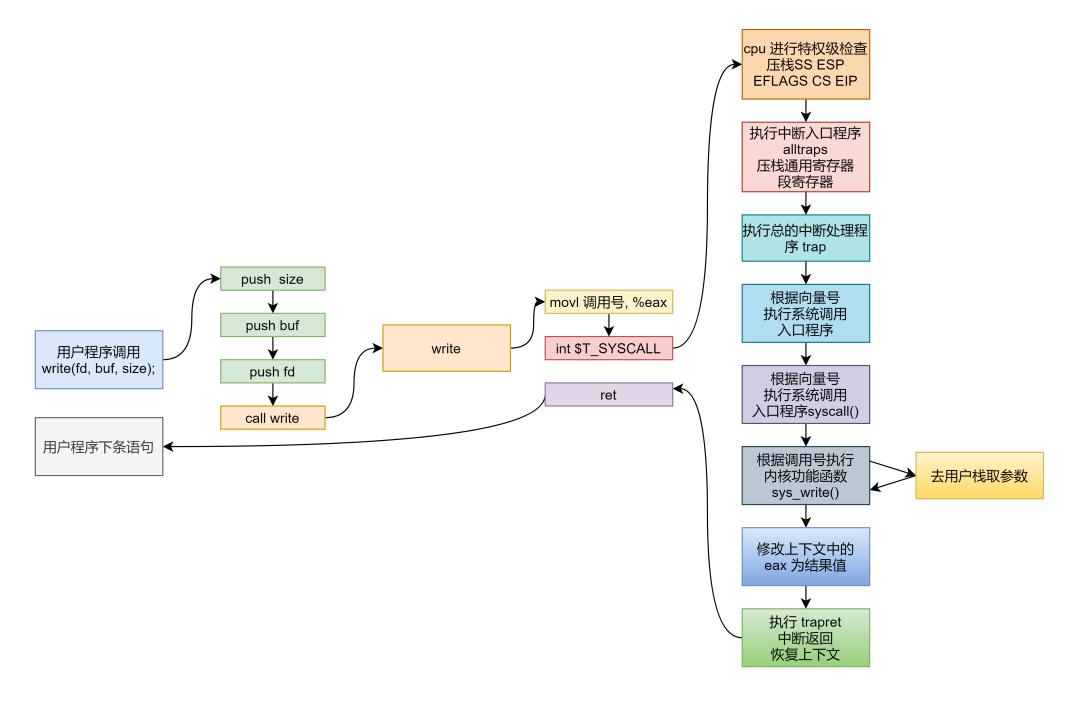
这是以 write 系统调用为例的系统调用过程图,图是丑了点,不过这条线应该捋得还是挺清晰的,好啦,本文就到这里,有什么错误还请批评指正,也欢迎大家来同我讨论交流学习进步。
往期推荐
点个在看你最好看
