
前言
这绝不仅仅是一篇讲内联意义的文章
参考我的学习过程,可能对你的知识整合有很大帮助
之前写了一篇总结c++面试的文章,被大佬纠出来很多关于内联的问题与错误。抱着不误导别人的态度(也因为上篇文章承诺要给大家深入分析一下内联函数),我在最近的一个月里抽了很多时间去重新研究inline,确实学到了很多以前不了解的知识。学习么~就是一个不断打破之前认知并重构知识的过程,每个人都是从一个什么都不懂的菜鸟逐渐成长为一个大牛的。
在这篇文章里,我会由浅入深的分析不同阶段的我对内联函数的认识,重构我的知识体系。即使你之前对inline不了解,也可以看得懂这篇文章。
由于篇幅比较长,会分成上下两个部分。另外,文中会有很多引用的参考链接,我会统一放到文末的位置。这次我也重新的对文章做了排版,方便大家阅读。(不过由于我公众号开的较晚,开启评论功能是遥遥无期了)
01:菜鸟阶段
上大学第一次接触C++,然后了解到了内联函数。啥是内联函数?简单理解就是编译时把函数的定义替换到调用的位置。
inline int Add(int a, int b)
{
return a + b;
}
int main()
{
int num1 = 1;
int num2 = 2;
int myNum = Add(num1, num2);
}
//这样的代码内联之后大概就是
int main()
{
int num1 = 1;
int num2 = 2;
int myNum = num1 + num2;
}
好的,感觉好像还挺简单的。啥?你问我啥是编译?嗯。。编译就是把你的代码通过编译器分析一下然后转换成计算机能直接读懂的语言(汇编),最后生成一个可执行的程序(或可被调用的库)。
当然,我这么解释有点不太权威,咱们再看看维基百科关于内联函数的定义:
在计算机科学中,内联函数(有时称作在线函数或编译时期展开函数)是一种编程语言结构,用来建议编译器对一些特殊函数进行内联扩展(有时称作在线扩展);也就是说建议编译器将指定的函数体插入并取代每一处调用该函数的地方(上下文),从而节省了每次调用函数带来的额外时间开支。但在选择使用内联函数时,必须在程序占用空间和程序执行效率之间进行权衡,因为过多的比较复杂的函数进行内联扩展将带来很大的存储资源开支。【参考1:内联函数维基百科】
那么内联函数有什么有点呢?当然是减少函数调用带来的开销了,几乎每本C++入门书籍、百科以及博客都是这么说的。不过,什么是函数调用开销?额,反正调用函数肯定要消耗CPU运算吧,肯定也有内存参与,肯定有开销,嗯。
另外,我还从书上了解一些相关的知识,如直接在类的头文件里面定义的函数都是自动内联的(并不对),内联相比宏定义有类型检查、可支持类的访问控制等优点。
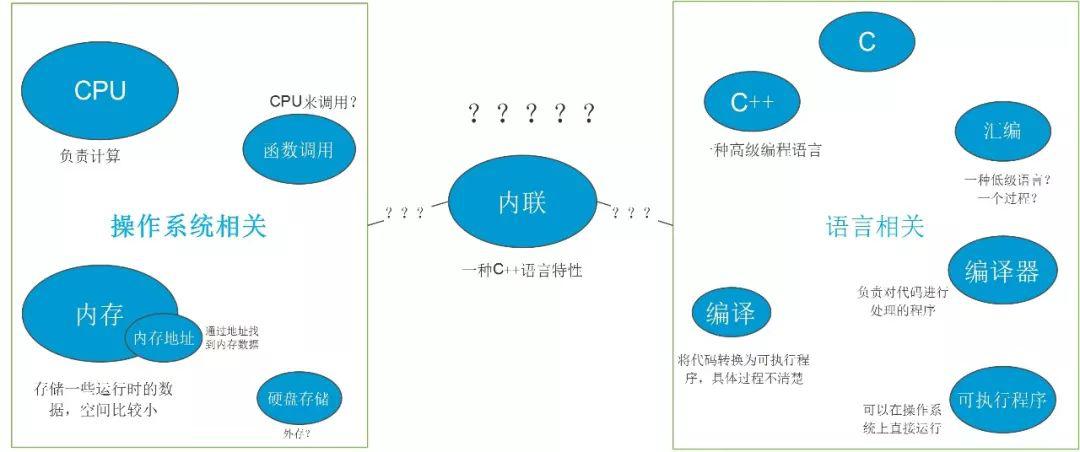
这时候的我知道的专业名词有:汇编、编译、内联、CPU、函数调用、内存地址,但是他们之间的关系几乎是一头雾水了。就如下图一样,
02:初识阶段
之前总是说减少函数调用开销,那么这个调用开销到底是指什么?这时候的我发现有一些面试里面会问到这个问题,所以还真有必要理解一下了。
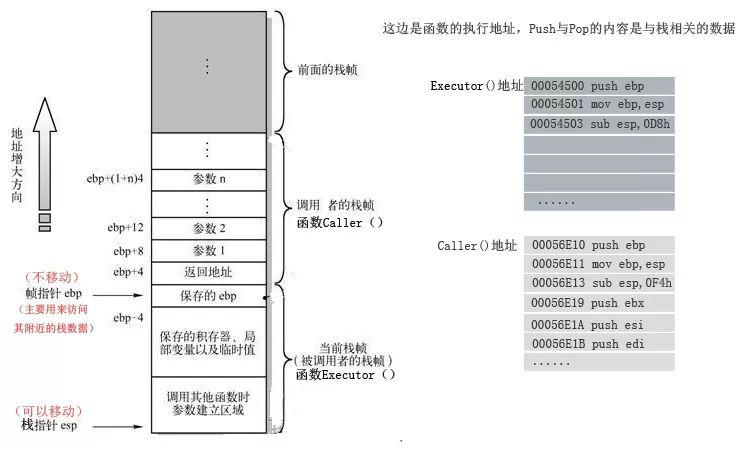
我们常说,C语言程序内存分为常量区、代码区、静态全局区、栈区、堆区。当我们的程序运行时,我们的编译后的二进制程序(这个二进制程序的分布格式差不多就是前面说的那几个区,里面会有各种汇编命令)就会被放到操作系统的内存里面,函数代码段被放在所谓的代码区,局部变量与函数参数被放在栈区。函数调用就发生在栈区里面,每次调用的时候会把当前函数的相关内容压入到栈里面处理寄存器相关的数据信息(所谓没有地址的右值一般就是通过寄存器存储的数据);然后,调用地址指向我们要执行的函数位置,开始处理函数内部的指令进行计算,当函数执行结束后,要弹出相关数据,处理栈内数据以及寄存器数据。【参考2:浅谈C/C++堆栈指引——C/C++堆栈很强大】
这个过程也就是所谓的“函数调用开销”。
到现在为止,我们不妨先总结一下消除函数调用的直接好处【参考3:Inline expansion 】:
1.它消除了函数调用过程中所需的各种指令:包括在堆栈或寄存器中放置参数,调用函数指令,返回函数过程,获取返回值,从堆栈中删除参数并恢复寄存器等。
2.由于不需要寄存器来传递参数,因此减少了寄存器溢出的概率。当使用引用调用(或通过地址调用或通过共享调用)时,它消除了必须传递引用然后取消引用它们。
当然缺点我们也应该了解,使用不当的话就会造成代码膨胀(也就是生成的可执行程序会变大);影响cache对数据的命中;如果你设计了一个函数库,调用你的内联函数还会造成客户代码的重新编译。
一般一级高速缓存里面会分为指令缓存(instruction cache)以及数据缓存(data cache),inline的使用不当对二者都可能造成影响。首先,过多的内联代码会使原来本可以存储到ICache的指令分散,导致指令缓存的命中降低,从内存取数据会严重影响效率。其次,inline会导致代码膨胀,增加可执行程序(动态库、静态库)体积,造成额外的换页行为,进而可能会导致数据缓存的命中率降低。
上面说的缺点还比较抽象,很多情况好像都可以接受。而还有一些特定情况,内联将会造成很严重的后果,如递归函数的内联可能造成代码的无限inline循环。所以编译器在这些特殊情况下会拒绝内联,常见的包括虚调用,函数体积过大,有递归,可变数目参数,通过函数指针调用,调用者异常类型不同,declspec宏、使用alloca、使用setjump等。不过这些情况编译器也并不是一定会拒绝,虚调用在某些情况下就可以被内联,会在第三部分细说。
这时候,我认识到,其实内联inline只是建议性的关键字,编译器并不一定会听你的,毕竟他比你更了解你的代码编译后是什么样子的,而所谓的内联也不单单是指inline这个关键字了,他本质上是一种编译器的优化方式。另外,在windows上平台我还经常能看到forceinline【参考4:MS Doc】(GCC上的【always_inline】)这样的关键字,字面意思是强制内联。不过经过查阅,发现一般只是对代码体积不做限制了,或者说在Debug模式(不不开启优化的情况)下也会尽量按照开发者的意愿去内联。无论如何,最终的决定权还是交给编译器去处理。
在这个阶段的学习过程中,我发现想理解程序的编译与运行,还不得不去看看程序的反汇编代码,看看编译器编译后的代码是什么样子的。毕竟很多时候,我们需要亲自手动操作才能真正的理解其中的原理。
虽然我上学时很讨厌这门课,但是我发现想大概看懂反汇编代码,并不需要非常完善的汇编知识,只要把常见的一些命令记住并理解就行了。【参考5:手把手教你栈溢出从入门到放弃 】

还是前面那段代码,测试在VS2017下的汇编代码(方法参考上图,代码主要看红色部分)
inline int Add(int a, int b)
{
return a + b;
}
int main()
{
int num1 = 1;
int num2 = 2;
int myNum = Add(num1, num2);
}
//Debug模式下无内联优化的汇编代码,需要跳到Add函数的地址去执行计算
int main()
{
//前面汇编代码省略
01232547 mov eax,0CCCCCCCCh
0123254C rep stos dword ptr es:[edi]
0123254E mov ecx,offset _5BD3FBCE_consoleapplication2.cpp (01247008h)
01232553 call @__CheckForDebuggerJustMyCode@4 (0123142Eh)
int num1 = 1;
01232558 mov dword ptr [num1],1
int num2 = 2;
0123255F mov dword ptr [num2],2
int myNum = Add(num1, num2);
01232566 mov eax,dword ptr [num2]
01232569 push eax
0123256A mov ecx,dword ptr [num1]
0123256D push ecx
0123256E call Add (01231726h)
01232573 add esp,8
01232576 mov dword ptr [myNum],eax
}
int Add(int a, int b)
{
//前面汇编代码省略
00891E67 mov eax,0CCCCCCCCh
00891E6C rep stos dword ptr es:[edi]
00891E6E mov ecx,offset _5BD3FBCE_consoleapplication2.cpp (08A7008h)
00891E73 call @__CheckForDebuggerJustMyCode@4 (089142Eh)
return a + b;
00891E78 mov eax,dword ptr [a]
00891E7B add eax,dword ptr [b]
}

//Debug模式下开启内联(/Ob2,参考上图)后的汇编代码,无需跳转到Add函数的位置,直接优化计算
int main()
{
//前面汇编代码省略
00F41F67 mov eax,0CCCCCCCCh
00F41F6C rep stos dword ptr es:[edi]
00F41F6E mov ecx,offset _5BD3FBCE_consoleapplication2.cpp (0F57008h)
00F41F73 call @__CheckForDebuggerJustMyCode@4 (0F4142Eh)
int num1 = 1;
00F41F78 mov dword ptr [num1],1
int num2 = 2;
00F41F7F mov dword ptr [num2],2
int myNum = Add(num1, num2);
00F41F86 mov eax,dword ptr [num1]
00F41F89 add eax,dword ptr [num2]
00F41F8C mov dword ptr [myNum],eax
}
通过观察汇编代码,我发现经过内联处理后的汇编代码可以直接进行两个参数的累加而不需要去调用Add函数。
当然你也可以在这里【参考6:Compiler Explorer】试试其他的编译器,如GCC、ICC、Clang。关于VS控制内联的参数,可以看这里【参考7:Microsoft Doc Inline Option】。
后来,我又看了《深入探索C++对象模型》这本书,印象很深的就是我们以为的代码在编译器处理后并不是我们以为的那样,里面有各种mangling【参考8:name mangling】,添加各种附加代码,那些看起来空空如也的的构造函数(析构函数同理)里面也可能有着几十行或者上百行的复杂代码。想象一下,你把这些构造代码内联的到处都是,你确定你的程序能得到优化么?
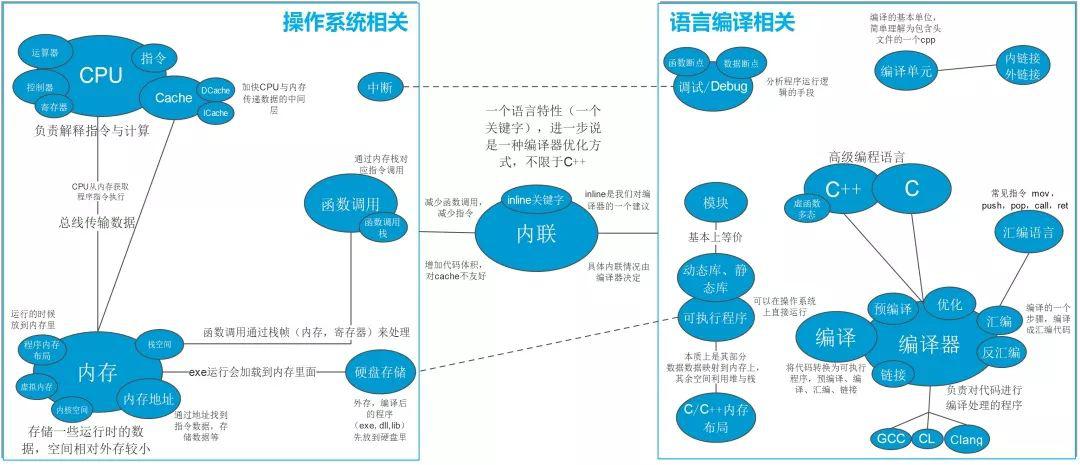
到这个阶段,我发现我能稍微的理解高级语言与汇编语言之间的关系,函数调用的基本原理,程序与内存之间的关系等,现在知识图谱大概变成这样了:
在下个阶段,我开始了解到一些编译器相关的内容,对内联的认识也进一步提升。
上篇文章总结了前两个阶段我对内联以及相关知识的理解,大部分内容都是我之前的理解。这篇文章我会继续深入分析,谈谈最近一个月学习的成果。
如果没有看过上篇,建议先阅读【这里】。文中会有很多引用的参考链接,而且很多内容都是英文的(建议找时间慢慢学习),我会统一放到文末的位置,很多链接不适合在微信里面查看,建议用浏览器打开。
03:进阶阶段
由于前一阵总结的文章被指出inline的总结内容有诸多不妥,所以我开始换一个角度去理解inline。说实话,大佬文章中很多名词我听都没听过,因为之前除了学完编译原理这门课之后就完全与编译器拜拜了(虽然我无时无刻不在用IDE提供的编译器)。
首先是关于内联的意义,前面说过内联的直接优点就是减少函数调用,这个是毋庸置疑的,但是他更大意义是它允许编译器进行进一步优化
【参考1:Inline expansion ;Reducing Indirect Function Call Overhead In C++ Programs;CppCon 2014: Andrei Alexandrescu "Optimization Tips" 】。
这点是我之前没有去想过,因为我们平时都在写业务代码,大部分情况下不需要考虑语言层面的问题。不过,我个人处于游戏行业,对“优化”一词还是比较敏感的,每次编译引擎(项目)所花费的时间、运行时的效率、调试效率、游戏帧数、打包时间等这些其实与我们的业务是息息相关的。一个庞大的项目一旦编译起来就花费很长时间,所以会有Debug、Development、Shipping等各种版本来满足我们不同情况下的需求。想要调试一个项目,当然是尽可能把优化都关掉才好;对于一个发行出去的游戏,当然是越小巧、高度优化、执行效率越高越好了。然而这些工作其实都是编译器在默默的帮助我们去做的(也可以说是各位编译领域相关的大佬帮我们做的),这时候我突然觉得我们连Debug与Release配置都搞不清真的有点对不起他们的工作了。
还是拿刚才的代码来说,我们再看一下内联后的汇编代码。
int main(){//......省略int num1 = 1;00F41F78 mov dword ptr [num1],1int num2 = 2;00F41F7F mov dword ptr [num2],2int myNum = Add(num1, num2);00F41F86 mov eax,dword ptr [num1]00F41F89 add eax,dword ptr [num2]00F41F8C mov dword ptr [myNum],eax}
对于任何一个能看懂代码的人,我们都知道myNum就是2,所以集人类智慧于一身的编译器也应该知道。除了把函数return a+b这段代码内联过来之后还应该直接算出答案,这就是说inline后的代码与之前已经完全不同了,所以编译器也有必要再看看这个地方有没有什么值得优化的。事实证明如果我把这个程序改为release版本的,这段代码就直接返回了,不客气的说,我连 myNum=2 这个都可以直接优化掉,因为这个局部变量看起来并没有什么意义。虽然不同的编译器的反汇编代码有所不一样,但是他们都在努力的用内联去调整编译后的结果。
朴素一点的理解,所谓的内联就是为了方便编译器看到更多源码信息,如果我们能把所有函数内联到Main函数里面,那理论上我们可以就可以得到最佳的优化代码,可能一段非常复杂的代码到最后只要一个指令就足够了。关于编译器的优化方案,非常多而且大佬们还在不断的优化提出更多的优化方案,常见的有死代码删除、循环不变代码外提、常数折叠等等。
【参考2:Category:Compiler optimizations Reducing ;Indirect Function Call Overhead In C++ Programs】
既然谈到新的优化方案,就正好说一下虚函数调用。在比较老的编译器上,我们不会去对虚函数内联,原因很简单,因为虚函数的执行属于运行时动态,我们需要动态查阅虚函数表来找到对应的虚函数。由于根本不知道运行的时候到底是哪个类会执行这个虚函数,当然也就不知道到底调用的是哪个子类下override的版本。但是,大佬们自然不会轻易放弃,能优化一点咱们就尽量优化一点。当我们的编译器可以分析出当前的程序,如
struct A{virtual ~A() {}virtual int foo() { return 0; }};inline int do_something(A& obj){return obj.foo();}struct B : A{virtual ~B() {}virtual int foo() { return 1; }};int main(){B b;return do_something(b);}
这样的代码的时候,我们就可以确定B就是继承树上的最终的子节点,也就可以将虚函数的查表调用改为直接调用进而进行内联优化,这种优化方式叫做Devirtualization。当然,这种代码确实过于理想的简单,我们常见的项目代码一定是分为多个编译单元的,编译器想进行跨编译单元的优化就还需要另一个方案,LTO(Link Time Optimization)即链接时优化。
【参考3: C++ Devirtualization Devirtualization in LLVM and Clang】
LTO顾名思义,就是在编译器进行链接时进行相关的代码优化,不同编译单元在链接的时候将其内部表示转储到磁盘,然后组成单个模块并进行优化。也因此,之前大佬纠正我说“写在cpp里面的函数也可以内联,每次修改会重新编译头文件增加编译时间这句话也说错误的”。【参考4:Link-time optimization for the kernel LLVM Link Time Optimization: Design and Implementation】
可是看完LTO相关资料后,我又产生了疑问,编译器优化不是还有IPO么。所谓IPO,Interprocedural Optimization,即过程间优化,传统的编译器是先将编译每个源文件成独立的目标文件,然后再通过链接器将目标文件链接成可执行文件(或库),其编译优化主要集中在每个源文件内部,而IPO可以打破这个局限对整个程序进行全局的优化。那么IPO与LTO是什么关系呢?看了wiki上的资料后,我大概理解为,LTO属于IPO的子集,IPO是一个可以在编译过程的任何阶段都能执行优化的解决方案,LTO只针对链接时优化,不过应该属于IPO一个最强有力的方案了。【参考5:Interprocedural optimization 现代C/C++编译器有多智能?能做出什么厉害的优化?】另外,C/C++这种纯编译型语言都可以做到链接时内联优化,而对于C#、Java这种半编译半解释型的语言,其优化的时机岂不是可以更为灵活随意了?
这时候我才发现,这么多关于内联的调整的优化好像都是编译器在搞,无论什么语言、什么平台,本质上都逃不过编译器的审核与优化。
那么,我们显示声明inline还有什么意义呢?好像我们写不写inline,没什么意义啊。只要是发行出去的版本,编译器自己决定,分分钟给你各种优化,你的各种inline建议好像都没什么意义了。不过,带着疑问我又去查了查资料,发现好像还没问想的那么简单,最起码inline还有两点意义:
1. 编译器并不是万能的,有时候人工的内联建议确实能解决一些编译器优化的盲点【参考6:libcxx修改1 、libcxx修改2 】
2. inline并不只是只有把函数内联到调用的地方这个意义,他还关系到ODR (定义与单一定义规则)。所谓ODR,就是任何变量、函数、类类型、枚举类型、概念 (C++20 起)或模板,在每个翻译单元中都只允许有一个定义(它们有些可以有多个声明,但定义只允许有一个)。不过具体一点的说又有很多种情况,对于非inline且odr-used的变量、函数,要求全局只能有一个定义;Inline变量、函数在每个编译单元都有有一个定义;需要使用类的时候,在每个翻译单元都需要一个定义。
例如:你如果把一个非成员函数放到.h文件里面并被多个编译单元包含,那么在链接的时候就会报错。因为非inline的全局函数在全局只能有一个定义,如果每个编译单元都有一个成员函数,编译器不知道链接哪一个。如果给这个函数加上inline的话,就可以解决这个问题。而如果你在多个cpp里面定义了函数签名完全相同的但是内容不同inline函数,也不会发生编译失败,不过具体链接到哪个版本的inline函数可能是未定义行为。【参考7:One Definition Rule 既然编译器可以判断一个函数是否适合 inline,那还有必要自己加 inline 关键字吗?最近看到陈硕的一本书提了一个问题,“编译器如何处理inline函数中的static变量?”】
关于优化,这里还涉及到一个概念, zero-overhead abstraction,即“零代价的抽象”(Rust里面叫zero-cost abstractions),简单来说就是抽象的同时不需要付出额外的代价,比如说vector<int> 数组在优化理想的编译器的发行版本下与int类型的数组开销应该是几乎相同的。因此,我们可以认为C++中的zero-overhead abstraction与编译器的优化是密不可分的,更进一步的说,C++语言本身的优良与编译器也是密不可分的。每当C++新的标准出来后,各大编译器团队都要及时的去支持这些新的特性,并兼顾语言的优化问题。【参考8:Rust所宣称的zero-cost abstractions是怎么回事?Zero-cost abstractions abstraction and hand-crafted code】
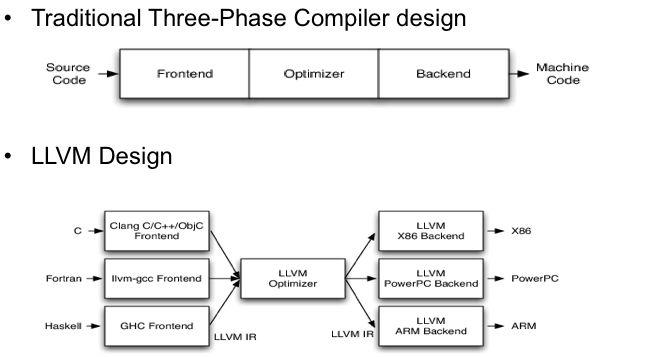
最后,再简单提一下LLVM。前面的很多链接里面都提到了LLVM(很久以前,LLVM曾经是Low Level Virtual Machine的缩写,现在已经不是了),它是一个编译器基础设施框架,包含了我们编写编译器需要的一系列库(如程序分析、代码优化、机器代码生成等),并且提供了调用这些库的相关工具。Clang, llbc++, lld等项目就是基于LLVM开发的,Objective-C编译器也是基于LLVM开发的。LLVM的编译过程与传统的编译器有所差异(参考下图),中间会生成一套通用的与语言无关的中间语言LLVM IR,我们可以去阅读这个中间语言了解更多信息【参考9:测试工具】,所以编译优化与使用方式也是非常灵活(我目前在VS上还没有找到可以阅读的单个编译单元编译后的文件)。
我没有深入了解,更多内容可以【参考10:LLVM 谁说不能与龙一起跳舞:Clang / LLVM (1) 周末花了点时间看 LLVM IR, 闲扯几句 编译器LLVM浅浅玩 】
这段时间查了各种资料,算是勉强到了一个新的阶段。这个阶段的我开始关注了core language之外的东西——编译器,虽然研究的并不是很透彻,但是在概念上我对程序的运行编译、程序与操作系统之间的关系有了进一步的理解,有时候会觉得豁然开朗,看起来毫无关系的知识突然就联系在了一起。
知识图谱又稍微修改了一下:

也许这篇文章看完,你会觉得这个内联好像懂了以后对编程也没多少帮助,但正如我知乎上的评论所说的,
其实这个就像我们学的数理化那些,看起来生活中很少或者基本不会直接用到,但是里面的思想会影响到我们对事物做出的逻辑判断,甚至万一遇到问题了还能解决,就拿汇编来说,大部分做业务的程序员基本不会用到,但是一旦遇到问题甚至要在没有单步调试环境的下面debug,反编译后能看下汇编代码,调试起来还是会比不会汇编的人方便快捷很多。很多东西怕就怕万一用到了~
End
参考链接:
【1】.Inline expansion ;
https://en.wikipedia.org/wiki/Inline_expansion
CppCon 2014: Andrei Alexandrescu "Optimization Tips"
https://www.youtube.com/watch?v=Qq_WaiwzOtI
【2】.Category:Compiler optimizations Reducing ;
https://en.wikipedia.org/wiki/Category:Compiler_optimizations
Reducing Indirect Function Call Overhead In C++ Programs;
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.27.5761&rep=rep1&type=pdf
【3】.C++ Devirtualization
http://lazarenko.me/devirtualization/
Devirtualization in LLVM and Clang
http://link.zhihu.com/?http://blog.llvm.org/2017/03/devirtualization-in-llvm-and-clang.html
【4】.Link-time optimization for the kernel LLVM
http://llvm.org/docs/LinkTimeOptimization.html
Link Time Optimization: Design and Implementation
https://lwn.net/Articles/512548/
【5】.Interprocedural optimization
https://en.wikipedia.org/wiki/Interprocedural_optimization
现代C/C++编译器有多智能?能做出什么厉害的优化?
https://www.zhihu.com/question/43598164/answer/122186527
【6】.libcxx修改
https://reviews.llvm.org/D22782
https://reviews.llvm.org/D22834
【7】.One Definition Rule
https://en.wikipedia.org/wiki/One_Definition_Rule
既然编译器可以判断一个函数是否适合 inline,那还有必要自己加 inline 关键字吗?
https://www.zhihu.com/question/53082910
【8】.Rust所宣称的zero-cost abstractions是怎么回事?
https://www.zhihu.com/question/31645634
Zero-cost abstractions
https://ruudvanasseldonk.com/2016/11/30/zero-cost-abstractions
Interview with Bjarne Stroustrup - abstraction and hand-crafted code
https://stackoverflow.com/questions/20134585/interview-with-bjarne-stroustrup-abstraction-and-hand-crafted-code
【9】.测试工具 http://ellcc.org/demo/index.cgi
【10】.LLVM
http://www.aosabook.org/en/llvm.html
谁说不能与龙一起跳舞:Clang / LLVM (1)
https://zhuanlan.zhihu.com/p/21889573
周末花了点时间看 LLVM IR, 闲扯几句
https://segmentfault.com/a/1190000002669213
编译器LLVM浅浅玩
https://medium.com/@zetavg/%E7%B7%A8%E8%AD%AF%E5%99%A8-llvm-%E6%B7%BA%E6%B7%BA%E7%8E%A9-42a58c7a7309