普通手机“随手”拍的雕像,一下就变成了精细的三维重建图。
水杯来回动的动态场景下,细节清晰可见:
静态场景效果也同样nice,狗狗突出的肋骨都被还原了出来:这是一种可对未知物体的6D姿态追踪和三维重建的方法。用于从单目RGBD视频序列中跟踪未知物体的6自由度运动,同时进行物体的隐式神经三维重建,方法接近于实时(10Hz)。这种方法适用于任意刚性物体,即使视觉纹理大部分确实,仅需在第一帧中分割出物体,不需要任何额外的信息,并且不对智能体与物体的交互模式做任何假设。可处理大幅度姿态变化、有遮挡视频
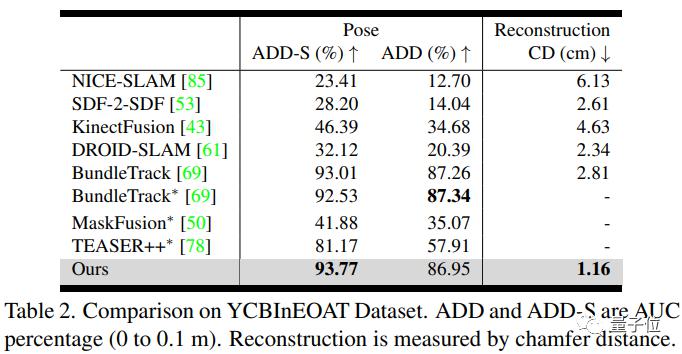
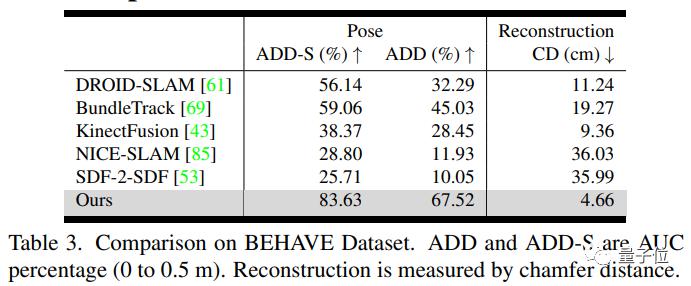
该方法的关键是一个神经物体场,它与姿态图优化过程同时进行,以便将信息稳健地累积到一致的3D表示中,捕捉几何和外观。方法自动维护了一组动态的姿态内存帧,以便这些线程之间进行通信。它能处理具有大幅度姿态变化、部分和完全遮挡、无纹理表面和高光反射等具有挑战性的视频。作者展示了HO3D、YCBInEOAT和BEHAVE数据集上的结果,证明了我们的方法显著优于现有方法。野外测试
该方法不仅适用于更具挑战性的动态场景,还适用于此前经常被考虑的静态场景(移动相机)。因此实现了比专门设计用于静态场景的那些方法更好或相当的结果(即文章开头展示动图)。与SOTA对比
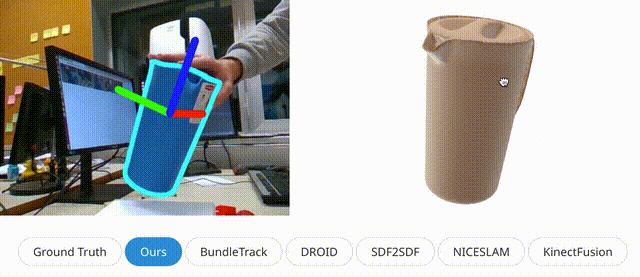
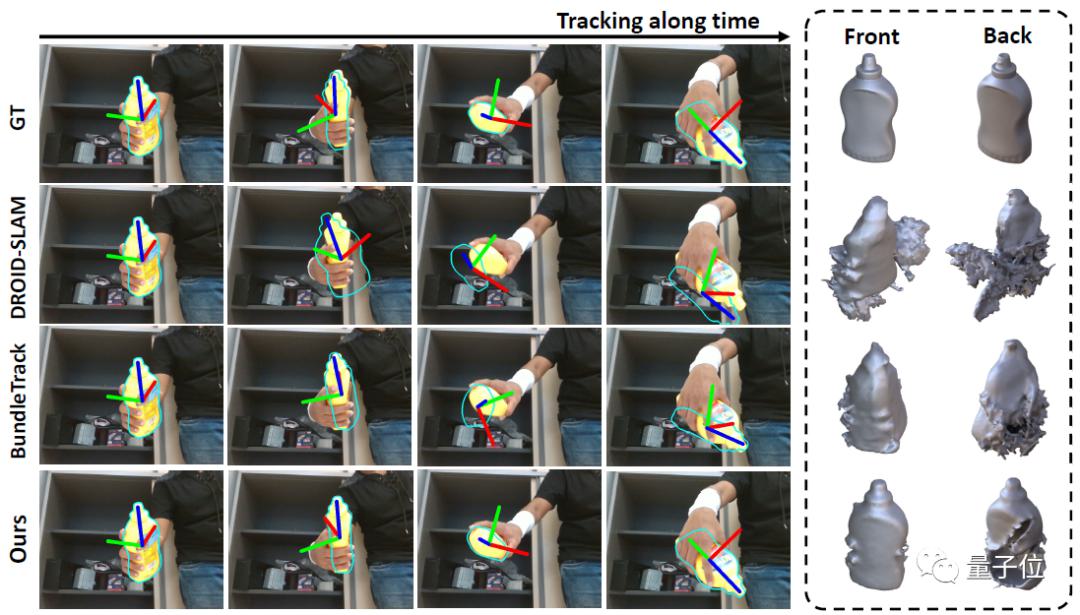
左图:6自由度姿态跟踪可视化,其中轮廓(青色)以估计的姿态渲染。值得注意的是,如第二列所示,我们的预测姿态有时甚至会纠正GT的错误。右图:每种方法输出的最终3D重建的正面和背面视图。由于手部遮挡,视频中的某些部分永远不可见。虽然从相同的视角渲染网格,但是DROID-SLAM和BundleTrack的显著漂移导致网格错误旋转。问题设置
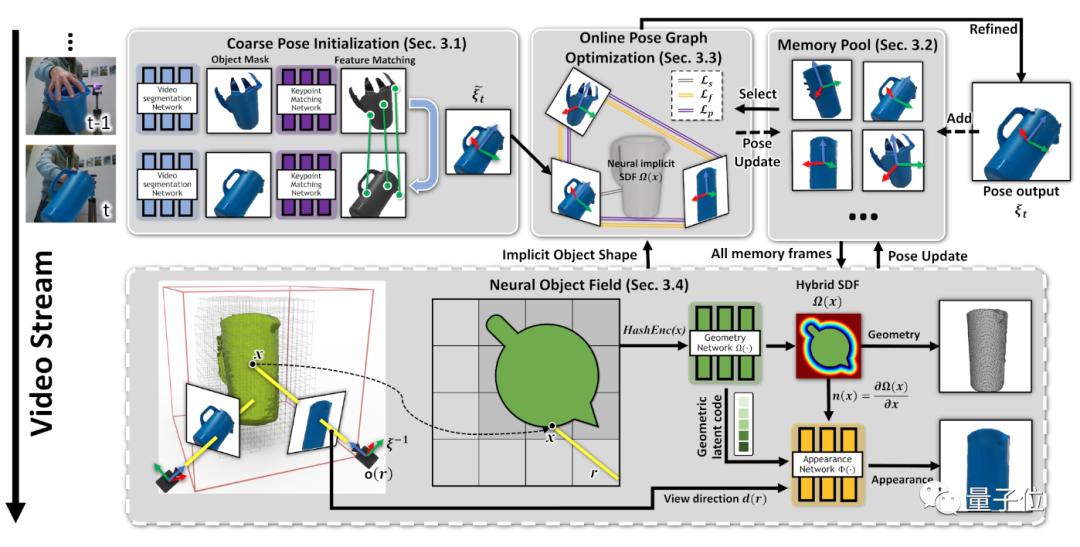
给定一段单目RGBD输入视频以及仅在第一帧中目标物体的分割掩码,该方法能持续追踪物体的6-DoF姿态并重建物体的3D模型。处理的物体是刚性的,但不依赖其特定丰富的纹理 - 方法适用于无纹理的物体。此外,不需要物体的实例级CAD模型,也不需要物体类别的先验知识(例如事先对同一物体类别进行预训练)。首先,在连续的分割图像之间匹配特征,以获得粗略的姿态估计(第3.1节)。
其中一些带姿态的帧被存储在内存池中,以便稍后使用和精化(第3.2节)。
从内存池的子集动态创建位姿图(第3.3节);在线优化与当前姿态一起联合细化图中的所有姿态。
然后,这些更新的姿态被存储回内存池中。
最后,内存池中的所有带姿态的帧用于学习神经物体场(在单独的线程中),该场建模了物体的几何和视觉纹理(第3.4节),同时调整其先前估计的姿态,使姿态跟踪更加鲁棒。
项目地址:https://bundlesdf.github.io/IEEE Spectrum
《科技纵览》
官方微信公众平台