

2009年,IMAX 3D电影《阿凡达》风靡全球电影市场。几年后,初音未来3D演唱会吸引了所有动漫迷的目光。最近,AR/VR 3D头戴设备带动了元宇宙的蓬勃发展。3D显示领域的每一项进步都带来了重要的社会关注和经济效益。
为了获得更逼真的视觉体验,主流的3D显示商业解决方案大多基于双目视觉原理。
然而,与观察真实的3D物体不同的是,观看者佩戴设备获取3D信息时,视觉焦点的深度保持不变。这种聚散度调节冲突(VAC)使观看者容易出现视觉疲劳和眩晕,从而限制了用户体验。
计算机生成全息术(CGH)可以从源头上避免聚散调节冲突的产生。实验装置简单紧凑。CGH受到了学术界和工业界的极大关注。它被视为3D显示的未来形式。
原则上,CGH基于衍射计算将3D对象编码为数字二维 (2D) 全息图。然后将二维全息图上传到由平面波照明的空间光调制器 (SLM)。在一定距离处获得 3D 物体的光学重建。CGH在广泛的3D显示器中具有潜在的应用,例如头戴式显示器、平视显示器和投影显示器。
如何高速、高质量地生成二维全息图是目前该领域的一个关键问题和重要研究方向。
最近,清华大学精密仪器系研究团队提出了一种模型驱动的深度学习神经网络,称为4K-DMDNet。实现高质量高速全息图生成,实现高保真4K彩色全息显示。
该研究以「4K-DMDNet: diffraction model-driven network for 4K computer-generated holography」为题,发表在《Opto-Electronic Advances》杂志上。

https://www.oejournal.org//article/doi/10.29026/oea.2023.220135
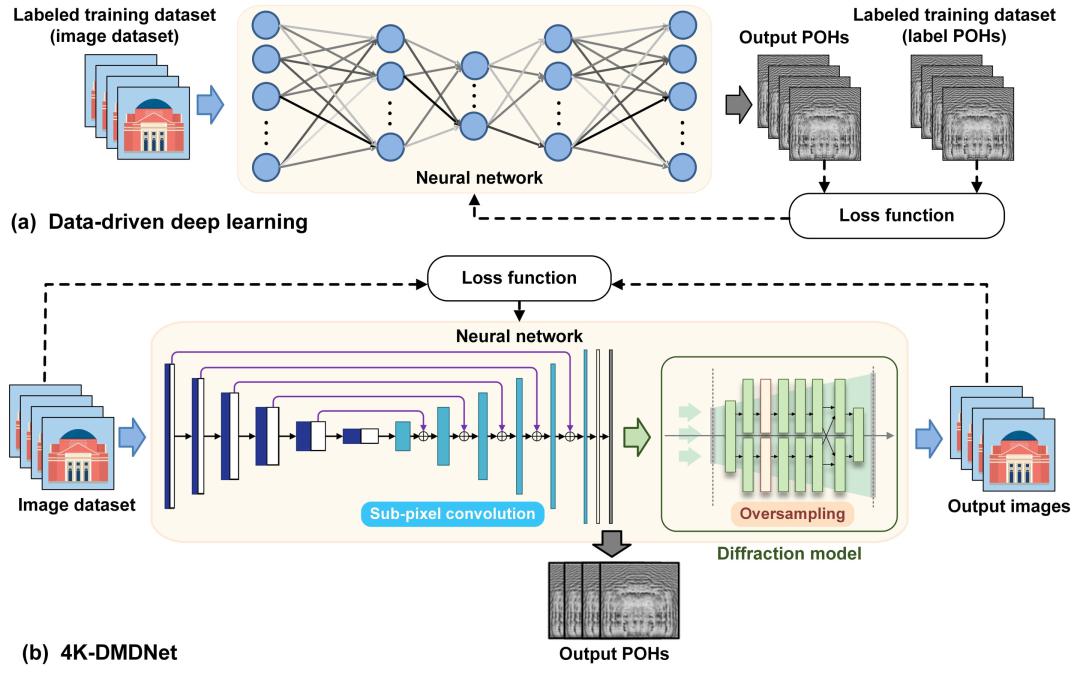
图示:(a) 数据驱动深度学习与 (b) 4K-DMDNet在训练原理方面的比较。
由于SLM的局限性,计算出的全息平面上的复振幅分布需要转换为仅振幅全息图或仅相位全息图 (POH)。其中,POH生成过程是典型的不适定逆问题。它面临的挑战是解决方案可能不是唯一的、稳定的或现有的。
迭代算法可以将POH生成过程转化为优化问题。可以获得具有良好收敛性的数值解。然而,这些算法面临计算速度和重建质量之间的权衡。
深度学习强大的并行处理能力为解决优化问题带来了革命性的进步。深度学习对CGH也产生了深远的影响。
预先获得3D物体的训练数据集和对应的全息图数据集,作为神经网络的输入和输出。训练神经网络学习它们之间的映射关系。经过训练的网络可以实现对训练数据集之外的显示目标输入的快速预测。有望同时实现高速和高质量的全息图生成。
利用神经网络进行全息图生成的想法早在 1998年就由日本研究人员提出,但受限于当时计算机的软硬件性能,仅取得了初步的成果。
随着GPU和卷积神经网络(CNN)的广泛应用,当前的硬件和软件性能更适合CGH的数学特性。基于学习的CGH发展迅速。
2021年,麻省理工学院的研究人员提出了一种 「张量」 全息网络,可以在智能手机上实时生成2K全息图。

图示:不同类型图像的光学重建:(a) 彩色图像和 (b) 二进制图像。
为了获得准确的网络预测,训练数据集和相应的全息图数据集需要一个耗时的生成过程。此外,由于网络只是学习输入和输出之间的映射,全息图数据集的质量限制了训练结果的上限。
为了突破数据驱动深度学习的上述局限性,提出了基于模型驱动深度学习的全息图生成方案。
网络不是预先生成全息图数据集,而是通过使用逆问题的正向物理模型作为模型驱动方法中的约束来训练网络。网络因此可以学习如何自主编码全息图,突破全息图数据集大小和质量的限制。
然而,传统的模型驱动的深度学习网络需要在显示目标上进行迁移学习才能获得更好的性能。额外的时间成本限制了模型驱动深度学习的实际应用。
该研究提出的4K-DMDNet使用残差U-Net神经网络框架。Fresnel衍射模型作为训练过程的约束。它能够在没有迁移学习的情况下生成高保真 4K 全息图。

图示:4K-DMDNet生成和重建4K全息图的过程
一般来说,网络的预测性能受到网络有限的学习能力和训练过程中约束不足的影响。
为了应对学习能力有限的挑战,4K-DMDNet引入了亚像素卷积的方法。在上采样路径中,通过使用卷积将通道数扩展了四倍,空间扩展是通过像素shuffle获得的。亚像素卷积方法解决了传统转置卷积中加入大量零参数进行空间扩展的挑战。它在不改变整体数据量的情况下,将上采样路径中的可学习参数增加到原始大小的四倍。它有效地增强了网络的学习能力,从而显着提高了重建的清晰度和保真度。
为了解决训练过程中约束不足的挑战,4K-DMDNet在 Fresnel衍射模型中引入了过采样操作。频域中的约束区域被零填充以在计算过程中将尺寸加倍。根据空间采样间隔和频率范围之间的映射,重建满足Nyquist-Shannon采样定理。在收紧频域约束的同时,提高了衍射模型的精度。
https://techxplore.com/news/2023-02-model-driven-deep-high-fidelity-4k-holographic.html
文章来源:ScienceAI

IEEE Spectrum
《科技纵览》
官方微信公众平台
