
算不对就用各种方法多算几遍,中间步骤也检查一下,原来这套教学方法对大模型也管用。

方法
与已知结果相一致。通过将解决方案与已知的结果进行比较,可以评估其准确性并进行必要的调整。当问题是一个有既定解的标准问题时,这一点尤其有用。 多重验证。从多个角度处理问题并比较结果有助于确认解的有效性,确保其既合理又准确; 交叉检查。解决问题的过程与最终的答案一样必要。核实过程中的中间步骤的正确性,可以清楚地了解解的背后的思维过程。 计算验证。利用计算器或电脑进行算术计算可以帮助验证最终答案的准确性。
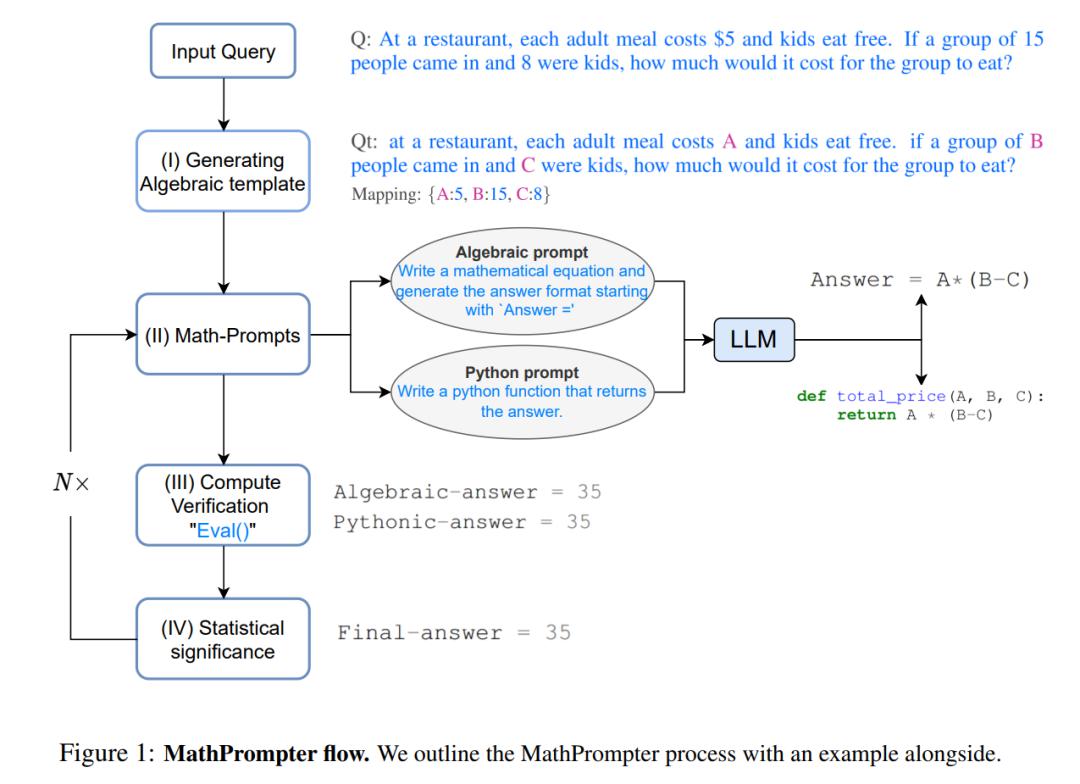
问:在一家餐厅,每份成人餐的价格是5美元,儿童免费用餐。如果有一个15人的团体进来,其中8个是儿童,那么这个团体要花多少钱吃饭?
Q_t:在一家餐厅,每份成人餐的价格是 A 美元,儿童免费用餐。如果有一个B人的团体进来,其中C个是儿童,那么这个团体要花多少钱吃饭? 映射:{A:5, B:15, C:8}
代数prompt:写一个数学方程并生成以 “answer =” 格式开头的答案。 Python prompt:编写一个返回答案的Python函数。


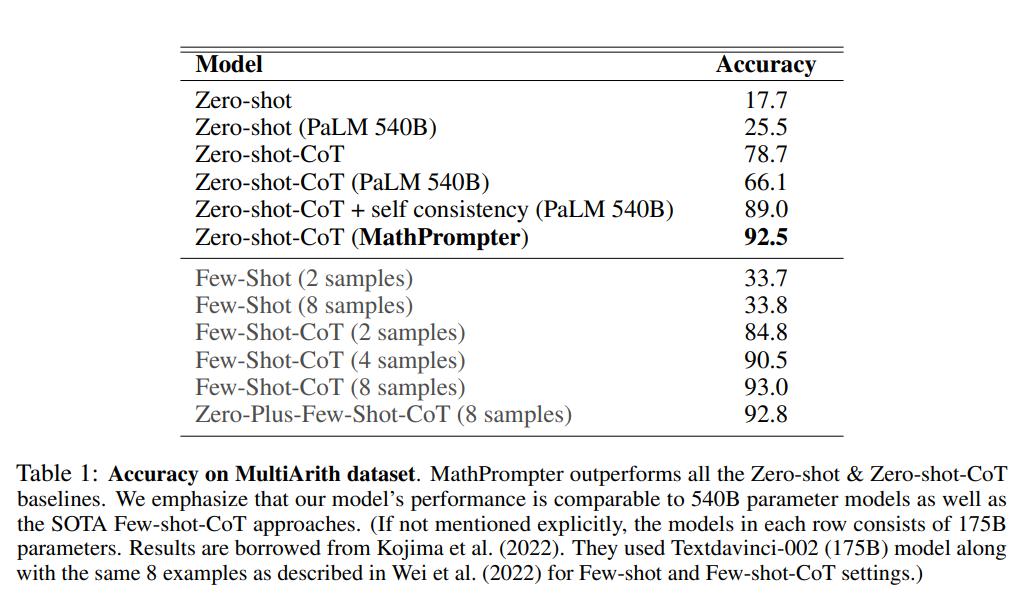
实验结果

文章来源:机器之心

IEEE Spectrum
《科技纵览》
官方微信公众平台
