
北京大学的一个研究团队提出了可以降低存储编码计算复杂度的编码方法,一种改良的RS 码,即基于GF(2)域的RS码——BRS码,实现了以简单的编解码方式获得最快速的编解码速度。
互联网、移动设备和点对点通信的发展导致数据不断增长。2010年,全球线上和线下数据第一次超过1泽字节(1021字节),从此我们步入了泽字节的时代。而IDC的报告显示,预计到2020年,全球数据总量将超过40泽字节(相当于4万亿吉字节)。如此海量的数据是宝贵的财富,也是棘手的挑战:该如何存储海量数据,并保证其可靠性呢?
分布式存储系统是较为公认的、能有效解决海量数据存储问题的方案。这种系统将数据分散存储在多个独立的设备上,利用多个存储服务器分担数据负荷。但分布式系统往往由成百上千个存储节点组成,节点故障往往会导致灾难性后果,容错性面临巨大挑战。为了保证数据的可靠性,分布式存储系统需要引入冗余机制,使节点间有多个物理网络可以互为备份。纠删码可以极大地提高数据存储空间利用率,所以相比于简单易行的多副本策略,越来越多的存储系统选择使用纠删码策略。但是,纠删码过高时,计算复杂度会延迟存储系统的反应时间,降低存储系统可靠性以及增大CPU能量消耗。
以RS码为例,RS编码是一种在分布式存储环境下可容错的编码方式,它将需要存储的数据分成K个数据块,每块大小为L,通过编码矩阵将这K个数据块生成N个编码块,校验数据块为M,其中N =K+M,每个编码块存储在一个存储节点中,则当编码块损失数量不大于M时,系统可以从任意K个编码块中修复所有数据块。RS码需要复杂的有限域运算,特别是有限域的乘法运算,会极大地增加纠删码的计算复杂度,引起性能的下降。
不过,北京大学的一个研究团队已经掌握了可以降低存储编码计算复杂度的编码方法——一种改良的RS码—— BRS(Binary Reed-Solomon)码。BRS码是一种高效、快速、满足最大距离可分离(MDS)特性的纠删码,它把原始的K个数据块编码生成N个编码块,在分布式存储环境下可修复节点数据损失。我们定义MDS特性为N个编码块中任意的K编码块均可解码出原始的K个数据块。BRS是具有MDS特性的纠删码,是一类特殊的MDS码,它在编码过程中只用到了异或运算,并且编码的计算量达到了最少,因此能够以简单的编解码方式获得最快速的编解码速度。在满足单位数据冗余最优数据可靠性的纠删码(如传统RS编码和最优CRS编码)中,BRS码的编码计算复杂度是最低的。
但是该种码有一个致命的缺点,就是它的ZigZag解法要求系统块的长度必须大于数据块的长度,并且这个长度与K和M的乘积成正比。这个冗余长度会给实际应用带来影响。为此,研究团队在此基础上进行改进,得到了一个改良的BRS码,可以将冗余长度缩短至原来的一半以下。
传统的RS码构造都是基于有限域GF(q),而BRS码的优越性在于它编码生成编码块的时候,只用到了异或运算。RS码使用范特蒙德矩阵作为数据的编码生成矩阵,将该生成矩阵的逆矩阵作为解码矩阵。为了保证RS码的MDS特性,传统RS的编解码运算都是在一个大的有限域上进行的。而BRS码算法使用的编码运算只包括了数据块的移位和异或操作,将编解码运算实现在一个大小为2的有限域GF(2)上,解码运算使用ZigZag方式解码,改善了传统RS编码的性能,提高了编解码的运算速度。
在编码过程中,BRS码将原始数据块(Blocksize)S平均分成K个块,假设每一块数据块有l比特的数据;构建编码块M,M共有N-K个块(即K=N+M,这里的加法均为异或操作);在每个节点存储数据,节点1的数据为S0,结点2的数据为S1,以此类推。
当有节点失效而出现数据丢失时,BRS码将使用一种非常快速的解码算法去修复丢失的数据,这成为BRS码的另一个优越性。在BRS码的解码过程中,有一个必要条件:完好的检验数据块的数目要大于等于损失的原始数据块的数目,否则无法修复。
BRS码使用ZigZag算法进行解码。首先从现在的校验块中得到第1个损坏的字节,然后用这个字节去解出第2个字节,再用第二个字节去解出第3个字节,直到解出最后一个字节。整个过程如同抽丝剥茧一般,根据线索将迷题一层层解开,当将茧剥完时,也就得到了所需要的数据。因为整个ZigZag解法的方法固定又简单,可以非常高效地进行解码。根据迭代公式,每循环1次,就能算出2个比特的值。如果每个原始数据块长度为10比特,则重复10次后,就能解出原始数据块中的所有未知的比特。以此类推,就完成了数据的解码。
为了更加直观地了解BRS码的性能及其与CRS码和RS码的对比,我们假设每个数据块的大小为32768字节,共8或10个原始数据块,生成4个校验数据块。
因为编码原因,BRS码的校验数据块大小为32768字节,原始数据块大小为32768-7×3×8=32600字节。在同样的假设下,CRS码的数据块大小为32768字节,刚好为4的整数倍,不需要改变,每个条带(Strip)长度为8096字节。
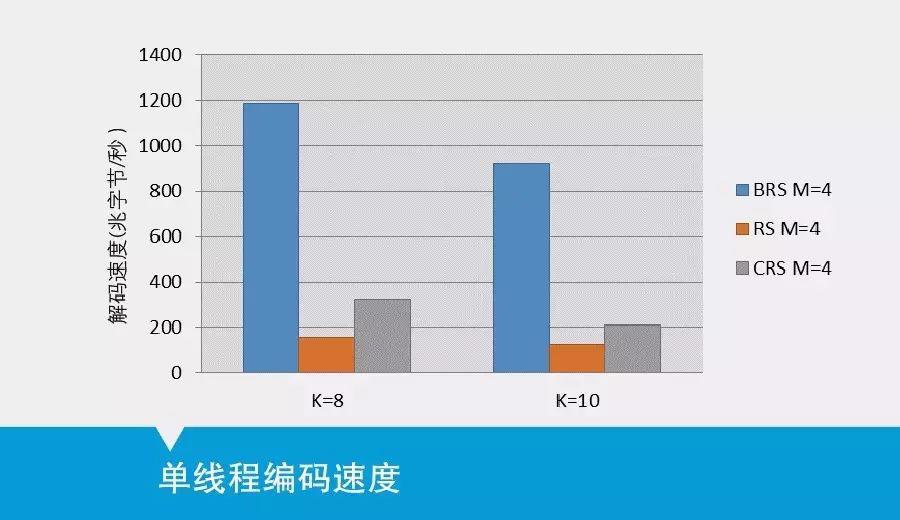
对上述8个原始数据块生成4个校验数据块,实验连续重复10万次。编码速度为编码生成的总数据量与编码总时间的比值,其中,编码生成的总数据量为32千字节×4校验块×10万次=12500兆字节。
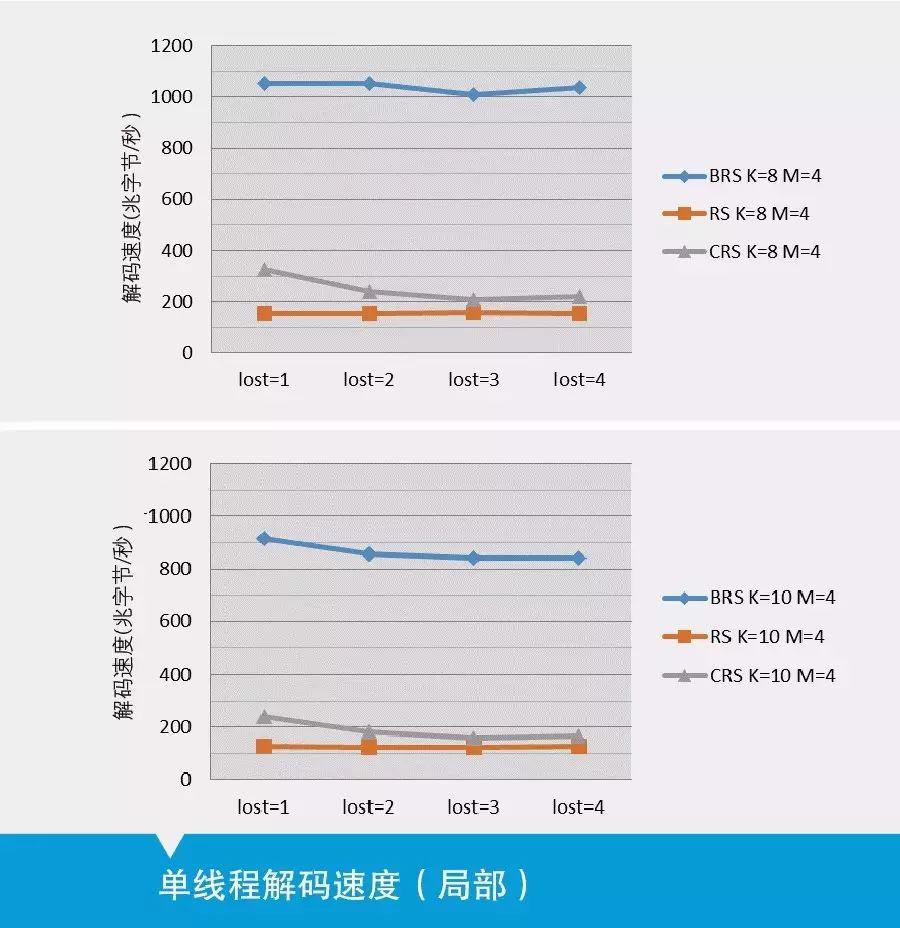
实验表明,在编码速率上,单核处理器下BRS码的编码速率约为RS编码的6倍,约为CRS编码的1.5倍,满足“相比RS编码,编码速度提升不低于200%”的目标。在同样条件下,对于不同缺失个数,BRS码的解码速率约为RS编码的400%,约为CRS编码的130%,满足“相比RS码,解码速度提升100%”的目标。
在分布式系统应用日益普及的今天,在分布式存储系统底层使用纠删码存储数据可以增加系统的容错性,在相同的冗余度下,与传统的副本策略相比,BRS码可以成倍地提高系统的可靠性。
BRS码可应用在分布式存储系统中,例如在HDFS平台中,可以使用BRS编码作为底层数据编码。同时,BRS码在性能上的优势和其与CRS编码在编码方式上的相似性,使得BRS码可以替代CRS编码在分布式系统中使用。如今,Github上已有开源BRS码的C语言实现,在分布式存储系统的设计与实现中,可以使用BRS编码方式存储数据,实现系统自身的可容错性。
纠删码引入冗余机制导致的系统复杂性被BRS码以简单的编解码方式一一化解,并得到了极为快速的编解码速度,这种BRS码真正做到了繁简两相宜。
(编辑:小智)
